
Genixly team
-
November 26, 2025
Core Principles of Cloud Data Warehouse Architecture and How Leading Vendors Apply Them
Lear more
Prompt tree replaces traditional keyword research in LLM visibility tracking by mapping how prompts evolve across answer engines and decision stages.
As search shifts from ranked results to synthesized responses, a prompt tree is quickly becoming the foundation of how teams test and understand visibility in AI-generated answers. The old logic of keyword lists and volume-based tracking no longer explains why some brands appear — and others disappear — in LLM outputs. And below, we explain why it happens.
The realm of AI-driven discovery is very different from the dimension of SEO and SERPs. Here, questions don’t exist in isolation and are not fixed. They evolve, usually following the familiar path: a broad query turns into a constrained one, comparisons follow exploration, and validation questions surface before a decision is made. What if you try to apply the good old SEO approach that has always been efficient, treating these moments as disconnected prompts?
In this case, you will only bury the understanding of how answer engines actually guide users. In GEO, traditional keyword research breaks down, opening a vacant position for something new, answer engine optimization (AEO) and generative engine optimization (GEO) require. Something that we describe below.
This article explains what a prompt tree is, what it replaces, and why keywords alone are blind for LLM visibility measurement. You will encounter a realistic prompt universe, separate label prompts by decision stage, discover how to force models to surface real options, and learn how to avoid prompt sprawl that produces noise instead of insight.
If you’re still testing LLM visibility with isolated prompts or oversized prompt libraries, you’ve come to the right place. Below, we discuss the GEO layer that turns experimentation into something you can actually monitor. And don’t forget to visit our Complete GEO Framework.
Keywords still work in SEO because they create the foundation of optimization techniques. It happens due to the very nature of search engines, which were built to retrieve documents.
Let’s explain the classic search model in simple terms. A query acts as a routing signal here. The engine matches keywords to indexed pages, ranks those pages based on relevance and authority, and lets the user compare and evaluate. Even when intent is complex, it can still be compressed into simple but longer phrases — longtail keywords. It makes keyword research viable. And despite volume, difficulty, and rank being imperfect proxies for evaluating your visibility in search engines, they map reasonably well to how discovery works. AI search, however, is entirely different, but we have not yet finished with SEO and keywords.
Keyword-based optimization, by its nature, has allowed optimization to outperform quality. A page doesn’t need to be the best answer — it needs to be the best optimized answer. With the right keyword placement, internal linking, backlinks, and technical hygiene, a merely good piece of content may outrank a genuinely superior one. SEO rewards structural compliance as much as substance, and in many cases, more.
That tradeoff is tolerable because users still control the final decision. If the top result looks disappointing, you can still scroll, compare, and decide. In this model, ranking higher only increases exposure, not authority. Luckily, visibility and trust are still earned at click-time, not granted by the engine. Generated answers have changed that balance, and it’s finally time to proceed to the GEO part of this chapter.
How do LLMs work? Rather than exposing a ranked list for users to interrogate, they compress multiple sources into a single response and implicitly endorse certain options over others.
Because AI still needs to understand your content, but it is not a human being, you need to help it. As a result, models often recommend not the objectively best option, but the best option among those it can clearly comprehend (You can learn how to make your content speak the same language with LLMs here: GEO for Product Pages and GEO for Local Businesses).
In that context, however, being “well optimized” but weak in substance is far less effective. The model is not looking for keyword density — it is looking for signals that support confident synthesis: clear positioning, explicit tradeoffs, credible constraints, and defensible claims.
This is why traditional keyword optimization and, as a result, research feels increasingly blind in GEO. Consider the following two cases:
1. Two prompts that share no keywords express the same decision intent may trigger similar AI-generated answers: “Offer the best CRM for a small business, budget-friendly, easy to learn” and “Propose a solution to manage my customers: I run a tiny online store and don’t want to spend much money on it.”

2. Two prompts that share the same keyword but have different intent may trigger entirely different answers: “Best CRM for SMBs with big team, AI-features, automation, and no budget constraints” and “Best CRM for SMBs with a team of one manager and a limited budget.”

This shift is what breaks keyword-centric thinking for answer engine optimization (AEO) and generative engine optimization (GEO). While keywords highlight a general topic, answer engines reason over details: intent, constraints, and tradeoffs. As a result, measuring visibility through isolated terms misses how AI systems actually surface options and recommendations.
What replaces keyword research is a structured map of how questions relate to each other across stages of decision-making. Not a spreadsheet with keywords listed in alphabetical order, but a query universe. And that structure has a name — Prompt Tree. It becomes the foundation of modern GEO measurement.
Let’s draw a simple analogy. Imagine you are in a new city, trying to understand how to navigate via public transport. However, you only have a spreadsheet with hundreds of station names, line numbers, and addresses. Everything is technically accurate, but nothing tells you how the system actually works. You can’t see where metro lines branch, where trams intersect with buses, or how routes connect across the city. That’s what keyword lists and oversized prompt libraries feel like in AI search.
Now look at a public transport map. It shows metro branches splitting and merging, tram lines intersecting with subway stations, and bus routes filling the gaps between them. Although the map doesn’t obsess over geographic precision, it prioritizes structure, order, and connectivity. You immediately understand how to get to the point of your destination, even if you’ve never been here before.
Prompt tree works the same way.
While traditional SEO relies on keyword lists, a prompt tree replaces that abstraction with something closer to reality: a connected prompt universe. Each node in the tree represents a real question a user might ask, and each branch reflects how that question naturally evolves as constraints tighten, options narrow, and tradeoffs surface.
In this model, prompts are not independent. They are related. A broad exploratory question leads to a narrower follow-up. A comparison triggers validation questions. A risk concern leads to a decision check. The tree structure captures that flow, rather than flattening it into a spreadsheet of terms.
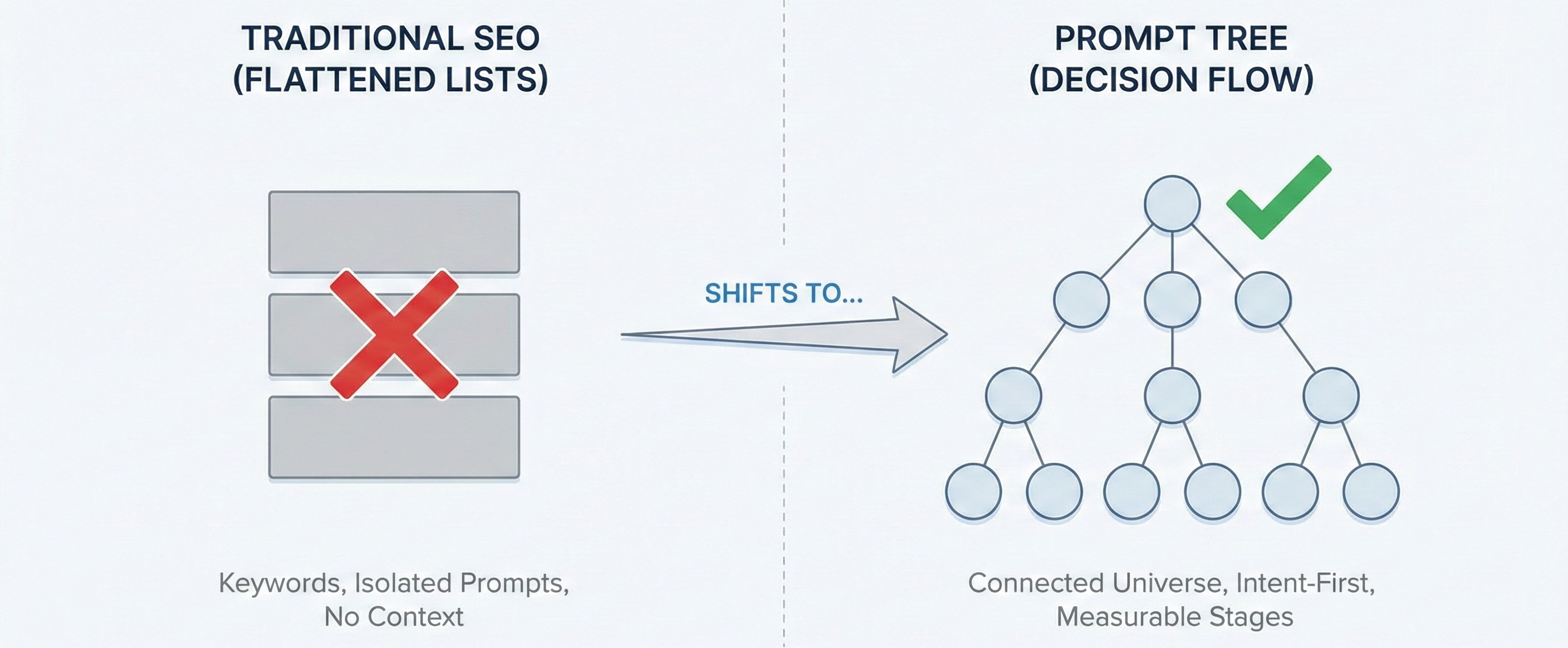
This is what a prompt tree replaces:
Unlike keyword lists, a prompt tree is intent-first. Prompts are grouped by what the user is trying to accomplish, not by shared phrasing. Two prompts with no overlapping words can belong to the same branch if they express the same underlying decision need.
Unlike prompt libraries, a prompt tree is purposefully constrained. Its goal is not exhaustive coverage of every possible wording, but sufficient coverage of the decision space. This approach focuses on removing redundancy, merging near-duplicates, and creating a system where each prompt represents a distinct question rather than a stylistic variation.
Most importantly, a prompt tree is measurable. Because prompts are organized by intent and stage, you can track how often your brand appears across entire branches — not just individual leaves. That turns visibility from a series of anecdotes into a system-level signal.
In practical terms, a prompt tree done this way becomes the foundation for modern AEO and GEO. It defines what you test, what you monitor, and what “coverage” actually means in AI-driven discovery.
Once prompts are structured this way, the next step becomes obvious: labeling them by stage — so you know where in the decision journey you win, and where you disappear.
Not all prompts are equal. However, the distinction becomes even clearer when you introduce decision stages. In answer engines, users don’t move from ignorance to decision in one step. They circle, refine, test assumptions, etc. What looks like a single question on the surface is usually part of a longer decision loop. Stage-labeling prompts make that behavior visible — and measurable.
Rather than organizing prompts by keyword similarity, a prompt tree organizes them by the following five decision stages:

Labeling prompts by stage does two things keywords never could.
First, it reveals where visibility breaks down. A brand may dominate exploration but vanish during validation. Another may appear only after deep narrowing, indicating high friction. Ignore those stage labels, and all these patterns become invisible, collapsing into noise. Let’s draw another analogy.
You look at the map and see a building. But that’s all you see. You don’t know how many floors it has or what’s inside. From above, you only recognize its outline and its street number. Nothing more. But switch to the street view, and you will get a better understanding of that building. Get the 3d model of the building, and you will achieve a more complete picture. The more detailed the model is, the better you will know the location. That’s how we proceed to the second essential thing:
Labeling prompts by stage aligns measurement with reality. Answer engines don’t optimize for keywords — they optimize for helping users move forward. Stage-labeled prompts mirror that logic, making LLM visibility measurement about decision influence, not mention counts. It’s like exploring a detailed 3d model compared to its 2d representation.
But once prompts are structured by stage, it is essential to ask how detailed your “3d model” is: Do the prompts actually force the model to surface real options — or does it stay safely generic?
That’s where option-forcing prompts come in.
Most prompts fail not because they are badly written, but because they are too safe. Let’s see what it means.
The problem is that a large share of prompts used in AI search testing invite explanation instead of choice. They ask what something is, how something works, or why something matters. The model responds correctly — with education, definitions, and general guidance — and never needs to surface actual brands, products, or providers. Unfortunately, such prompts are useless from a visibility standpoint.
That’s why it is important to focus on option-forcing prompts, which are designed to remove that escape hatch. Instead of allowing the model to stay abstract, they explicitly require it to surface options, alternatives, or recommendations. They push the system into decision mode, where it must name things, compare them, or rule them out.
This is a fundamental shift from keyword thinking. While keywords only name topics in this new context, option-forcing prompts describe choice pressure. But what makes a prompt option-forcing?
A prompt becomes option-forcing when it does at least one of the following:
What unites these prompts is that rather than asking the model to explain the world, they ask it to take a position. That distinction matters because answer engines behave differently when forced to choose. They move from summarizing information to synthesizing judgments. Brands that never appear in explanatory answers may suddenly surface — others may be excluded — when the model is asked to decide. And this is precisely why option-forcing is essential for AEO and GEO. Visibility in AI systems is most powerful where decisions are made, not where definitions are given.
Option-forcing also reveals competitive dynamics that generic prompts hide. When the model must choose between alternatives, replacement patterns emerge. You see who displaces you, who you displace, and which criteria drive those outcomes.
Let’s summarize what we’ve learned in this chapter. Ignore option-forcing, and your prompt tree will collapse into an educational content audit. Use it, and the tree will become a true query universe that reflects how AI systems work across all decision stages and actually recommend, not just how they explain. But it’s not the end of the journey. The next challenge is scaling without noise. That’s where deduplication and coverage discipline matter.
Once teams start building prompt trees, a familiar failure mode appears quickly: Prompt Sprawl.
In a prompt sprawl, every wording feels slightly different, and every variation seems worth testing. Before long, you’re tracking hundreds of prompts that all express the same intent, learning nothing new from most of them. That’s why deduplication becomes as important as generation.
In a well-designed prompt tree, prompts are not unique because their wording is unique (it’s just the “Thesaurus Trap”). They are unique because the decision they force is different. If two prompts surface the same options, at the same stage, under the same constraints, they belong in the same node — no matter how different they look linguistically.
Coverage, on the other hand, is about ensuring that the full decision space is represented. Not every possible phrasing, but every meaningful angle. These axes define how users — and answer engines — differentiate options.
Too much dedupe, and you miss important contexts where visibility breaks. Too much coverage without dedupe, and you create noise that masks real patterns. A well-disciplined prompt tree avoids both extremes. It limits prompts per stage, merges near-duplicates aggressively, and prioritizes prompts that change what the model must consider, not just how the question is phrased. When prompts are deduped this way, results can be aggregated meaningfully: trends emerge, stability can be assessed, replacement patterns become visible, etc.
If you ignore dedupe, you don’t get insight. What really happens is that your spreadsheet grows, turning into an enormous prompt list. To learn more about LLM visibility measurement, follow this guide: How to Measure GEO Success.
When a prompt tree is built correctly, the output is not a list of prompts. It’s a prompt universe — structured, deduped, stage-aware, and stable enough to measure over time.
It’s a prompt tree with clear boundaries, where each prompt exists for a reason, each branch represents a distinct decision path, and coverage is intentional rather than incidental. With such a prompt tree, you can tell where it shifted and why when visibility shifts — not just detect that “something changed.”
Here, prompts are grouped by intent and stage, resulting in outcomes that can be aggregated meaningfully. You can track patterns instead of anomalies, stability instead of luck, and decision-stage presence instead of surface-level mentions. Visibility becomes something you can observe longitudinally, rather than a bunch of random metrics that you rediscover from scratch every week.
Building this for the first time does not necessarily mean you need to start from zero. If you’re ready to move from structure to measurement, you can build your first prompt tree in Genixly GEO and see how distribution-based visibility looks in practice. Contact us now for more information.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

