
Genixly team
-
March 12, 2026
How to Measure GEO Success: 5 Key Aspects To Follow
Lear more
This guide explains what the Complete GEO Framework is. Learn why the existing GEO workflows fail and what’s necessary for true Generative Engine Optimization.
%20Framework.jpg)
Welcome to the Complete GEO Framework guide, where we explain why existing AI search workflows fail and what’s structurally required to make generative engine optimization actually work. If you are still relying on dashboards, single-prompt tracking, or AI search analytics alone, we have some bad news — you are measuring fragments of reality, not controlling outcomes.
You may try as hard as possible, but the problem is not the effort. It is the existing gap around GEO and the desperate attempts to fill it in with some familiar means. Most teams approach LLM visibility the way they approached SEO: optimize content, track rankings, monitor mentions, and so on. All these common techniques still make a lot of sense when it comes to search engines that rank pages. However, everything breaks down when the same tactics are applied to answer engines that generate responses based on constraints, context, and evolving conversations.
In generative systems, visibility is not a static position. It is a dynamic outcome shaped by intent modeling, category memory, competitive displacement, trust grounding, and stage-level decision logic. And it requires an absolutely new paradigm of measurement, optimization, and control. That’s when a structured GEO workflow enters the game. Without it, improvements are inconsistent, attribution is unclear, and volatility is misinterpreted as progress. The Complete GEO Framework, however, addresses this gap.
The following article breaks down why traditional SEO workflows and modern AI monitoring tools are insufficient and outlines what a complete generative engine optimization system requires — from measurement foundations and conversation simulation to competitive intelligence, control loops, and tool evaluation. If your goal is not just to observe random episodes of your LLM visibility but to influence it entirely, you’ve come to the right place.
Most existing GEO workflows fail for the same reason early SEO experiments failed — they were created too early, when everything about the new industry was uncertain. So, let’s see what’s wrong with the common approaches to generative engine optimization. Below are 5 reasons why the existing GEO workflows fail in AI search optimization:
In simple terms, most GEO workflows fail because they function as analytics exercises rather than controlled optimization systems. Why did this happen? In many cases, it was a desperate attempt to fill the growing void of AI uncertainty. And, to be fair, that attempt was necessary. It served as a band-aid and, at the same time, as the first step toward finding a framework that actually works.
You can still rely on existing approaches to observe AI-generated answers. But observation alone will never allow you to systematically change them. So what’s required instead? The complete Generative Engine Optimization Framework! Let’s explore why it is the only GEO approach you need.
To understand what the Complete GEO Framework is, we need to accept the following fact: generative engine optimization cannot be limited to a single tactic. You must rather consider it a system. Below, we help you build an understanding of this system layer by layer, starting with measurement discipline, realistic decision modeling, and competitive intelligence, and ending with operational control and experimentation.
The first section of the framework addresses a simple but critical problem: most teams don’t actually know how to measure LLM visibility correctly. They believe they do — or the marketers behind the tools they’ve purchased make them believe so — but it’s largely an illusion. Worse, it’s sometimes partially true, which makes it even more dangerous.
And, as we mentioned earlier, measurement based on a single prompt result is never reliable. Recognizing this limitation is the true starting point of your journey toward the Complete GEO Framework. So, why is it so critical to abandon the single-prompt approach?
The answer is fairly simple — LLM outputs vary, and they vary significantly. A single screenshot showing your brand once proves nothing about structural visibility. Two random screenshots are just as meaningless. Five? Still insufficient.
The Complete GEO Framework requires something fundamentally different. This is where the concept of distribution becomes central. According to it, measurement must occur across prompt families and repeated runs — not isolated checks.
Following this principle, the Complete GEO Framework replaces traditional keyword research with Prompt Trees. Instead of grouping queries by phrase similarity, you organize them around decision intent within structured Prompt Trees. What about keywords, you may ask? They remain essential in SEO. However, keywords alone cannot align GEO measurement with how users actually think, reason, and ask questions inside AI systems. Prompt Trees can.
But be careful: even a well-designed Prompt Tree is not enough if your prompts are randomly generated. Validating whether prompts reflect real user behavior is a critical part of the Complete GEO Framework. Mandatory prompt evidence evaluation is what makes the system work — full stop. Without it, you have no way to ensure that your prompts mirror actual phrasing patterns, constraints, and intent rather than hypothetical test cases.
The Complete GEO Framework also requires recognizing that visibility shifts across different stages of a decision journey. In most cases, this journey unfolds across five stages: Explore, Narrow, Compare, Validate, and Decide. This structure allows you to measure your brand’s inclusion in AI-generated answers contextually — not as a single global score, but as stage-specific visibility aligned with real decision dynamics.
Finally, volatility must be acknowledged. LLM outputs fluctuate — sometimes subtly, sometimes dramatically. If you ignore this reality, you risk mistaking randomness for progress. This is why the Complete GEO Framework incorporates a Noise/Stability Index. It ensures that shifts in visibility are interpreted probabilistically rather than emotionally.
At this stage, GEO measurement becomes structured, realistic, stage-aware, and volatility-conscious. And this is only the beginning of the journey.
Once your GEO measurement is structurally sound, the next question becomes: Are you acting at the right moment? It may sound abstract at first, but let’s clarify what that actually means.
Visibility in answer engines is dynamic. To better understand this, recall the last time you asked an AI something. Did you stop after the first answer?
Probably not. Users rarely ask one question and stop there. They refine. They compare. They hesitate. They ask again. From the perspective of the Complete GEO Framework, measuring only the first answer ignores how decisions are actually formed. So what should be done instead?
The answer is obvious: You need to simulate a conversation. Conversation simulation introduces multi-turn testing. Instead of observing a single inclusion, the Complete GEO Framework observes how a brand behaves across evolving constraints. Does it survive comparison? Does it remain present when pricing is introduced? Does it appear when the model is asked to choose?
This is where metrics such as Path Win Rate and Decision Capture Rate become meaningful. Path Win Rate measures competitive presence across branches. Decision Capture Rate isolates the final recommendation moment — when the system moves from listing options to suggesting a choice.
And these are not the only metricks usud in the Complete GEO Framework. Routing Quality, for instance, expands the perspective further. It explores where AI sends the user, even if the brand is recommended: direct-to-brand, marketplace, aggregator, etc. Routing is important because it affects conversion control. And ignoring it means losing this control. Sentiment Drift adds another layer. Over time, framing patterns can accumulate. If these patterns introduce doubt, the doubt multiplies, and a brand may lose preference without losing mention frequency.
This is where the Complete GEO Framework shifts from simple inclusion measurement to decision-stage analysis. It treats visibility as part of a dynamic journey rather than an isolated event. But let’s take it a step further and examine the competitive intelligence layer within the framework.
After modeling internal performance and decision flows, the Complete GEO Framework expands outward into a competitive structure. Why? Because answer engines do not simply retrieve brands independently. What they do is construct associative networks and competitive relationships. That’s why the Complete GEO Framework introduces Replacement Maps along with other indicators:
Timing is another critical dimension of the competitive intelligence layer within the Complete GEO Framework. The earlier you begin your optimization journey, the easier it becomes — especially if you start during the Wet Cement stage, the phase when early narratives within a category are formed. Over time, these narratives solidify into defaults, marking the beginning of the Hard Cement stage.
When a brand participates early in shaping definitions, comparisons, and positioning, it can influence long-term retrieval patterns. Once the cement hardens, influencing answer engines becomes significantly more difficult — though not impossible.
At that point, you have two options: compete aggressively within the established structure, or introduce new narratives that initiate a fresh Wet Cement cycle.
This is where the Framework reframes GEO as structural category intelligence rather than isolated performance tracking. And from here, the focus shifts from analysis to action.
The final dimension of the Complete GEO Framework transforms understanding into leverage. Monitoring alone is insufficient if it does not lead to controlled intervention structured as a continuous loop:
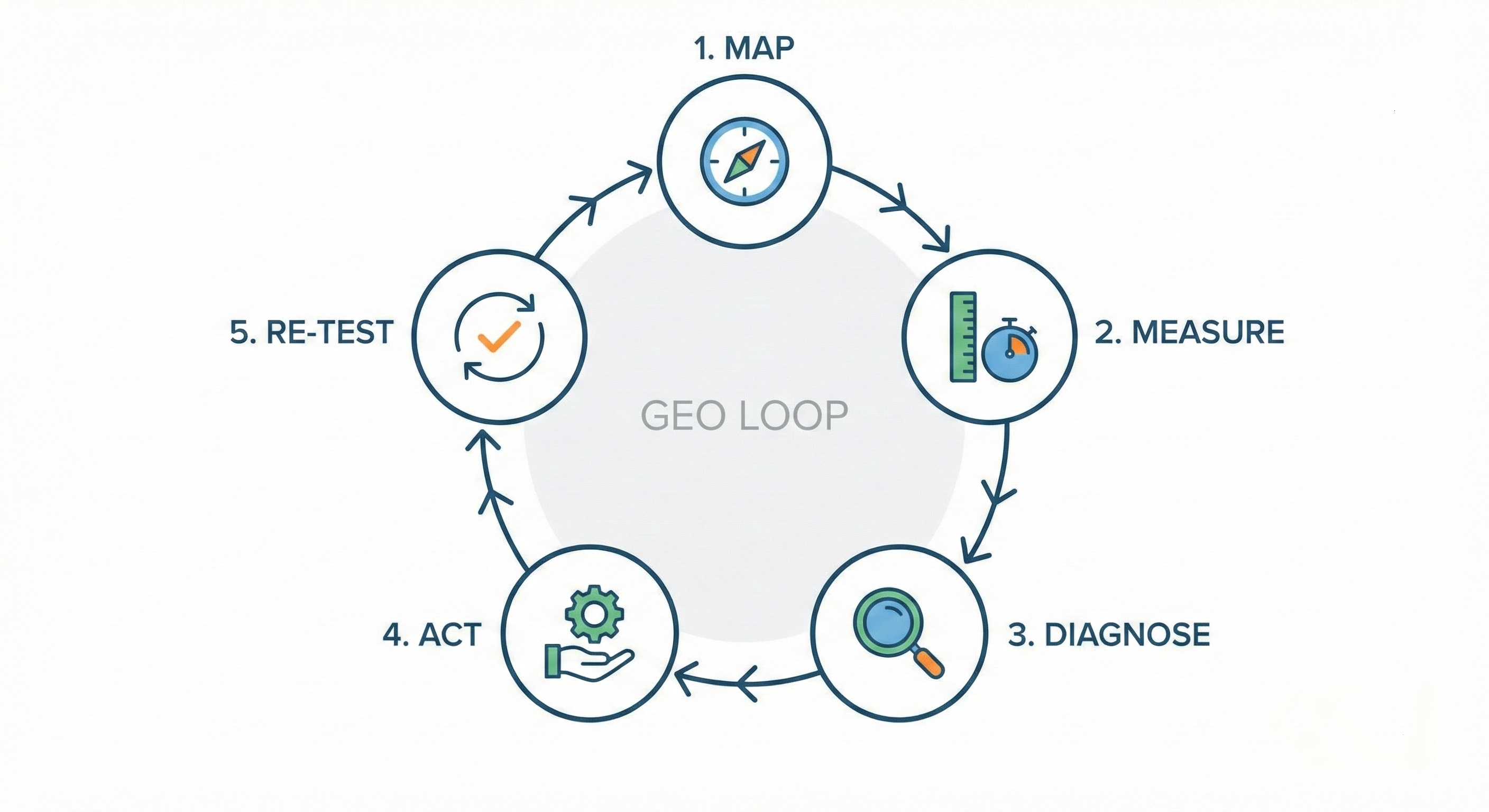
This loop turns insight into influence — and influence into measurable change.
Since the Map and Measure stages of the loop have already been covered, let’s focus on what comes next.
Diagnosis is a complex process that requires disciplined signal-to-cause mapping. For example, if you detect a drop in Decision Capture Rate, it may indicate unclear pricing. If AI systems begin routing users toward marketplaces during the Decision stage, it could signal weak trust framing.
When an issue surfaces, your task is not merely to observe it — but to trace it back to plausible structural causes. Only then can you take the right corrective action rather than applying random fixes that address symptoms instead of root problems.
Actions themselves are not generic content updates. They are structured playbooks aligned with specific KPI patterns — landing page restructuring, comparison frameworks, FAQ systems, risk-reversal assets, citation acquisition strategies, and more. At this stage, simply “writing more content” is almost useless. You must understand the root cause of the issue and address it with surgical precision.
What comes next is often ignored — or executed incorrectly — which renders many GEO efforts ineffective.
Once issues are diagnosed and corrective measures are applied, every action must be re-tested under controlled conditions. Prompt families, model settings, and constraints must remain stable. Only one variable should change at a time — the implemented improvement. This is the only way to determine whether a structural shift has occurred — or whether the perceived change was merely noise.
A monitoring or AI content optimization tool cannot guarantee that level of rigor. However, a true control-plane system aligned with the Complete GEO Framework can. Monitoring tells you where you appeared. AI content optimization helps improve workflows. A control-plane system goes further: it maps, measures, diagnoses, acts, and re-tests, verifying whether your interventions actually moved outcomes.
If you want to go deeper into the Complete GEO Framework, including detailed definitions, workflows, and examples, explore these materials:
As you can see, the Complete GEO Framework is not a collection of isolated tactics. It’s neither monitoring combined with AI content optimization. The Complete GEO Framework is a structural response to how answer engines actually operate. And it is fundamentally superior to existing workflows.
The existing workflows fail, and they fail for predictable reasons:
They optimize documents instead of decision paths.
They monitor mentions instead of diagnosing causes.
They celebrate visibility spikes without testing for stability.
They treat dashboards as endpoints rather than inputs into a control loop.
They optimize content for the sake of optimization.
But generative systems reward neither passive observation nor random improvements. They reward alignment — with intent, constraints, context tags, competitive structures, external grounding, and more.
And none of that happens by accident.
When viewed as a whole, the Complete GEO Framework operates across four structural layers:
Each layer builds upon the previous one. Without measurement discipline, conversation simulation misleads. Without competitive intelligence, diagnosis lacks structural depth. Without control loops, insights remain observational.
When implemented across all layers, generative engine optimization becomes a system capable of influencing how AI-generated answers are constructed — not merely observing them. That is the structural coherence behind the Complete GEO Framework.
If you want to move beyond monitoring AI search analytics and implement a full control-loop architecture, Genixly GEO is built to operationalize the Complete GEO Framework. It connects prompt realism, distribution measurement, conversation simulation, competitive diagnostics, action playbooks, and verification-grade re-tests into one system. Contact us to learn more.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

