
Genixly team
-
November 26, 2025
Data Integrity in Ecommerce Integrations: The Foundation of Agentic AI Commerce
Lear more
This LLM prompt evaluation guide explains how to validate prompts using real signals, like PAA or autocomplete, and offers a prompt evaluation checklist.

In one of our previous posts about the single-prompt tracking mistake, we’ve already highlighted the importance of LLM prompt evidence evaluation. Since it’s the key aspect that makes the difference between measuring imaginary LLM visibility and gaining real insights, let’s say a few more words.
As teams move from keyword lists to prompt trees, a new risk emerges: prompts that look realistic but have no connection to how people actually ask questions. These prompts produce answers that look worth taking screenshots and deliver insights suitable for dashboards — yet fail to reflect real user behavior. Without validation, GEO starts to drift away from reality and toward theater.
This blog post explains how LLM prompt validation works and why it matters. We’ll break down what counts as real evidence, how to distinguish credible prompts from made-up ones, and how to evaluate prompt library quality before you trust any output. From PAA prompts and autocomplete phrasing to evidence bundles and confidence classes, the focus is not on generating more prompts — but on proving that the ones you track deserve attention. And don’t miss our Complete GEO Framework for more insights on LLM visibility.
Imagine you’re at a supermarket looking for a healthy snack — something high in protein and fiber, but low in carbs and calories. One product immediately stands out. The front of the package clearly states a specific amount of protein per portion. The design is clean, the claim is precise, and it feels engineered to catch exactly this kind of attention. As for the nearby products, they are not so catchy. They don’t even highlight protein, making them seem like weaker alternatives at first glance.
But when you turn the packages around and compare the nutrition tables, the picture changes. The product with the prominent protein claim turns out to contain less protein than several competitors, while also introducing more carbohydrates and more calories per serving. The quieter products — the ones without bold claims on the front — deliver better nutritional balance once you look at the standardized data side by side. The difference wasn’t visible in the slogan. It was visible on the nutrition label.
This is exactly how unvalidated prompts distort GEO work, making LLM visibility measurement useless. A prompt can look precise and “high-intent” on the surface. But without evidence, that precision may be cosmetic. Important tradeoffs — bias, artificial phrasing, or skewed constraints — remain hidden unless the prompt is evaluated against standardized proof. Thus, prompt evidence plays the same role as a nutrition table in LLM visibility measurement.
Signals like PAA alignment, autocomplete overlap, long-tail keywords/questions convergence, and thematic grounding don’t make prompts more persuasive. They reveal what a prompt actually represents and what it hides. Ignore prompt evidence, and GEO decisions will be driven by packaging. Embrace it, and they’re driven by the substance.
Most prompt libraries used for LLM visibility testing are not wrong — they’re imaginary. The problem is that they look quite convincing on the surface: long lists, clean categorization, and division by intent or stage make them look like nothing is wrong. But scratch a little deeper and the hidden truth reveals: many of these prompts were never asked by anyone, anywhere. The problem is that an average prompt library is invented by marketers in the best-case scenario. In the worst case, it is generated by LLMs. This is what we call the fake LLM prompt epidemic.
It happens for comprehensible reasons. Firstly, teams understand that keywords don’t work in GEO, so a new approach is highly demanded.
Secondly, AI can speed up the workflow. Even a few years ago, creating something as huge as a prompt library may have taken up to several days. Today, it’s a matter of a few clicks. The tradeoff is that you have to sacrifice quality, but who cares if potential customers are not aware?
In the best case, prompts are written to sound plausible, not to be verifiably real. The result is a prompt library that feels sophisticated but rests on assumptions instead of evidence. In the worst case, they are just randomly created because there is a general demand for prompts.
When you test visibility against made-up prompts, results become impossible to interpret correctly. A brand may appear dominant simply because the prompt favors its language. Another may disappear because the question is phrased in a way no real user would ever use. What looks like insight is often just prompt bias masquerading as measurement.
This is where the prompt library quality quietly collapses. Unlike keywords, prompts don’t come with built-in validation signals like volume or historical demand. And there is no obvious way to tell whether a prompt reflects a real question, a rare edge case, or pure imagination — unless you explicitly prove it.
The irony is that answer engines themselves are trained on real language. What it means from the standpoint of the LLM prompt evidence evaluation is that you stop testing how the system behaves in reality and start testing how it reacts to your own assumptions when your prompts drift away from real phrasing. And this is precisely why prompt evidence matters more than prompt creativity.
So, understanding the importance of prompt validation is the foundation. Now, we need to proceed to the actual steps towards its implementation. Although not all evidence signals are equal, we highlight the following five that consistently indicate that a prompt reflects real demand rather than imagination:
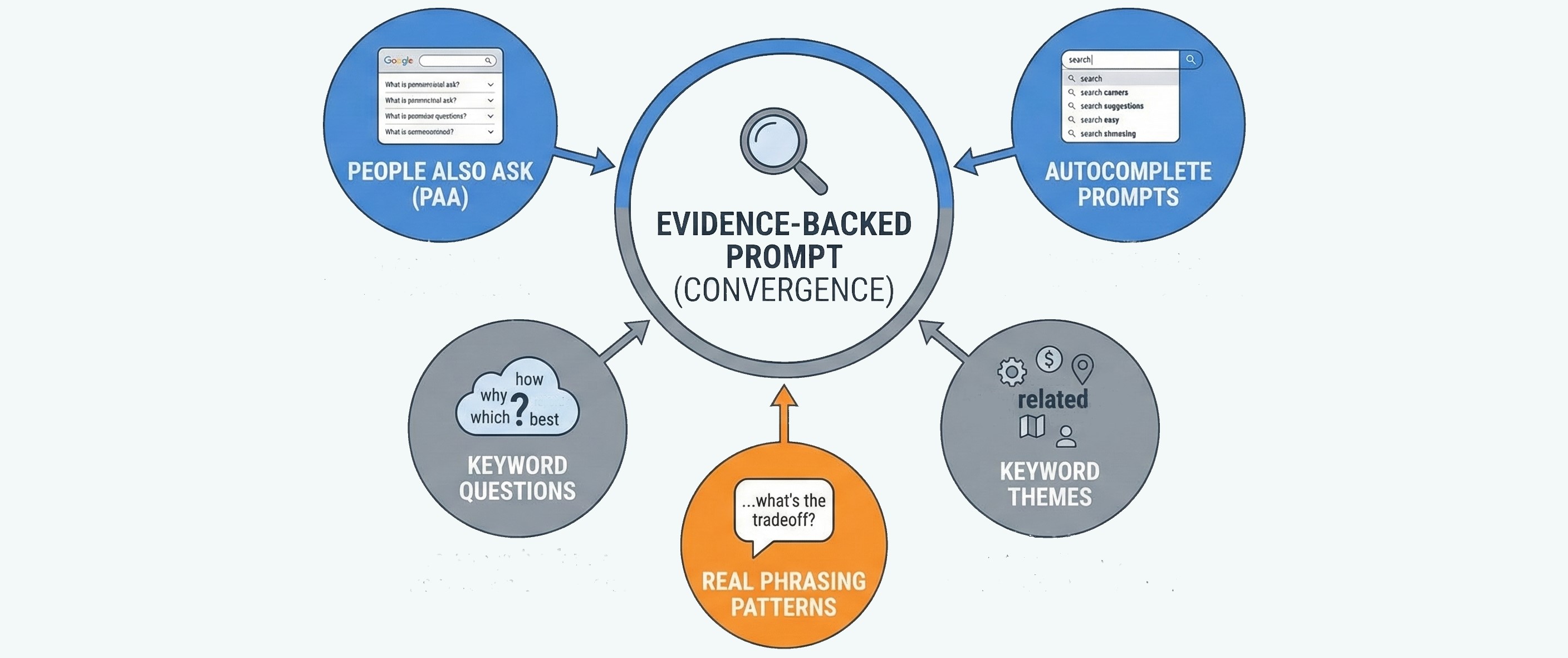
Treating these sources of truth separately, however, is a mistake because convergence is what makes them truly powerful. A strong prompt doesn’t rely on a single signal. It overlaps across PAA, autocomplete, and keywords, while matching how humans naturally phrase decisions. The more independent signals converge, the higher the confidence that the prompt represents real behavior.
One more essential aspect is to remember that you’re not proving that a prompt is popular. At the core of LLM prompt validation, the goal is to prove that a prompt belongs in the real query universe. Once evidence is established, the next step is to make it explicit and reusable. That’s where the next section comes in:
It’s not enough to see once that a prompt is real. You need to show why it exists, which signals support it, and how strong those signals are. That’s what an evidence bundle does: it turns intuition into something auditable.
The evidence bundle doesn’t judge performance or visibility. What it does is answer a simpler, foundational question: Does this prompt deserve to be measured at all?
At a minimum, an evidence bundle captures four things.
Together, these elements form a compact checklist of signals that can be reviewed, challenged, and improved. Prompts without evidence don’t get equal weight. Prompts with weak signals are flagged as exploratory. Prompts with strong convergence become anchors for measurement.
Once evidence is structured this way, it becomes possible to score prompts consistently — not by how well they perform, but by how credible they are as test inputs. That’s where prompt scoring comes in.
Once prompts are validated, the next task is to determine whether all validated prompts are equally useful.
Short answer is that they are not. Some prompts are strongly grounded in real demand but poorly framed for decision analysis. Others force choices but sit at the wrong stage. Prompt scoring exists to resolve that tension by ranking input quality.
The golden rule of LLM prompt scoring is fairly simple:
At a minimum, prompt scoring combines the following three dimensions:
Evidence score measures how well the prompt is supported by real-world signals. Prompts backed by multiple independent sources — PAA, autocomplete, long-tail keywords and questions, and strong thematic alignment — score higher than prompts with a single weak signal.
Stage fit score evaluates whether the prompt clearly belongs to a specific decision stage. A prompt that cleanly maps to Explore, Compare, or Decide is far more valuable than one that floats ambiguously between stages. Poor stage fit often signals synthetic phrasing or mixed intent, which leads to unstable outputs and misleading conclusions.
Option-forcing score assesses whether the prompt actually pressures the model to surface brands, products, or alternatives. Prompts that allow the model to remain educational or abstract score low here — even if they are real. Prompts that require comparison, selection, or exclusion score high because they expose competitive dynamics.
These three scores serve different purposes, but they work together.
A prompt with strong evidence but weak option forcing may be real, yet unhelpful for visibility testing.
A prompt with strong option forcing but weak evidence may produce interesting outputs, but shouldn’t be trusted.
A prompt with clear stage fit but weak evidence often belongs in exploratory research, not reporting.
Scoring makes these tradeoffs explicit. Instead of treating all prompts as equal, LLM prompt scoring allows teams to filter, prioritize, and weight prompts based on credibility and analytical value. Once prompts are scored, they can be grouped into confidence classes.
A prompt confidence class is the final stage of LLM prompt evaluation. It collapses multiple scoring dimensions into a single judgment: Can we rely on this prompt for decision-grade conclusions, or should we treat it cautiously?
This matters because not all prompts deserve the same weight in analysis, reporting, or decision-making — even if they look similar on the surface.
At a high level, confidence classes are built by combining three signals you already have: evidence strength, stage fit, and option-forcing clarity.

The purpose of confidence classes is context. Instead of arguing about whether a result “counts,” confidence classes make trust explicit. High-confidence signals carry more weight. Medium-confidence signals invite validation. Low-confidence signals are flagged as noise unless reinforced elsewhere.
This approach dramatically changes how the GEO work is interpreted. For instance, wins on low-confidence prompts stop inflating success, and losses on speculative prompts no longer trigger panic. Once confidence is formalized this way, something subtle but important happens: you stop reacting to every output in the same manner. The change reshapes what data you believe, what insights you prioritize, and what work you choose to do next.
Use this checklist to validate prompts for LLM visibility measurement. If a prompt fails multiple steps, it should not be used for reporting or decision-making.
If it sounds like something no one would type or say — it’s likely synthetic.
Only high-confidence prompts should drive reporting and decisions.
If you can’t explain why a prompt exists, you shouldn’t trust what it produces. To learn more about LLM visibility measurement, follow this guide: How to Measure GEO Success.
By this point in the LLM prompt evaluation, a pattern should be clear: single prompts don’t tell the truth, but prompt libraries without evidence are also useless.
The rise of answer engines has created a new failure mode. As keywords lose meaning, teams rush to replace them with prompts. Without validation, those prompts, however, make no sense. They are often imagined, overfitted, or shaped by internal language rather than real user behavior. The result looks sophisticated — but rests on unproven inputs.
LLM prompt proof is the correction.
By grounding prompts in observable signals — PAA prompts, autocomplete phrasing, long-tail keywords and questions, and thematic alignment — prompt validation restores contact with how people actually ask. Evidence bundles make that proof explicit. Prompt scoring clarifies which inputs are analytically strong. Confidence classes prevent weak prompts from distorting conclusions. Together, these layers redefine prompt library quality not by size or creativity, but by credibility.
Once prompts are proven, GEO work changes: measurement becomes more reliable, isolated screenshots lose influence, and trends start to appear, introducing more weight than anecdotes. And that’s the distinction between running tests and running a system.
If you want GEO work that produces insight instead of theater, prompt proof can’t be optional. It has to be built into the measurement layer itself. That’s exactly what Genixly GEO is designed to do — so you can trust what you measure, and ignore what doesn’t deserve your attention. Contact us for more information.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

