
Genixly team
-
November 26, 2025
Ultimate List of Customer Support Automation Tools: Top AI Solutions for 2026 & Beyond
Lear more
LLM visibility journey grammar describes how AI systems reason through the explore, narrow, compare, validate, and decide stages that replace funnels in GEO.

Today, we proceed to the LLM Visibility Journey Grammar — a discipline that explains why LLM visibility fails if brands still believe that AI systems still reason in funnels and what to use instead of them.
In AI search, discovery doesn’t unfold across pages, clicks, and sessions. The so-called messy middle takes place right inside the AI-generated answer itself. The model can compress exploration, narrowing down, comparison, validation, and decision into a single response or a short conversation, driven by how it reasons. And this is the exact point where GEO efforts usually break down.
While traditional customer journey models assume a linear progression and visible steps, AI-assisted purchases are way more different. In AI discovery journeys, those steps still exist, but they’re internalized. The model evaluates options, applies constraints, resolves tradeoffs, and manages risk before the user ever sees an answer. If your brand drops out at any point in that internal process, it usually never appears at the end. But don’t worry, you will soon learn how to address this issue.
Below, we are going to introduce you to LLM Visibility Journey Grammar — a stage model designed to match how people actually buy when decisions are mediated by answer engines. You will learn why funnels fail, how the messy middle is compressed inside AI answers, and how visibility must be measured across stages rather than aggregated into a single score. If GEO is about influence, journey grammar is how you see where that influence is gained — or lost — inside the model’s reasoning. And don’t forget to visit our Complete GEO Framework for more insights on LLM visibility.
When AI answers started replacing lists of links, a tempting assumption followed: the messy middle is gone. But it is a very simplified conclusion. It is easy to fall into the illusion that, if a single response can summarize options, compare tradeoffs, and recommend a choice, it feels like exploration, evaluation, and validation have collapsed into one moment. From the outside, the journey looks much shorter, cleaner, and almost linear. But that’s an illusion that disappears when you look under the hood.
But let’s return to the traditional search one more time. Here, the messy middle is visible. Users click multiple links and bounce between reviews, comparison pages, forums, and documentation. The complexity of decision-making plays out across tabs and sessions, so that it is easy to observe it in the shopping behavior itself.
What happens in AI-driven discovery? The same complexity still exists, but it’s now in the hands of the LLM, not the user. For instance, you can view it by clicking the Show thinking tab in Gemini:
When a model generates an answer, it cannot skip the evaluation. But rather than being performed visually, this evaluation takes place internally. The model weighs options, filters constraints, resolves tradeoffs, and suppresses uncertainty — all before producing a final response. What used to be a sequence of visible steps is now a compressed reasoning process that happens off-screen. Thus, we’ve come close to the next insight:
It means that if your brand, product, or data is missing from the internal reasoning phase, it won’t magically reappear at the end. Thus, compression doesn’t mean simplification. It means higher stakes. Let’s explain this thought in more detail.
In the compressed messy middle, there’s less room for recovery. You don’t get multiple chances to influence the user across pages.
What you get instead is one synthesized answer, where your visibility depends on whether the model can confidently include you while reasoning through the decision. And this is exactly why treating AI search as a faster funnel fails.
Linear funnels assume movement. They describe a user progressing step by step: awareness, consideration, evaluation, and decision. Each stage is triggered by a separate interaction, measured by a separate touchpoint, and influenced by a separate asset. This model makes sense when users navigate the web manually. LLM answers break that assumption.
Inside an AI-generated response, stages don’t happen sequentially. They often happen simultaneously because a single answer can introduce options, narrow them, compare tradeoffs, address risks, and suggest a next step — all in one output. What looks like a “top-of-funnel” question on the surface often triggers mid- and bottom-funnel reasoning inside the model.
Thus, linear funnels fail as a measurement model for LLM visibility simply because they assume that if you appear early, you’ll have opportunities later. In answer engines, there may be no “later.” If the model resolves the decision internally and excludes you during that reasoning, you don’t get a second chance to influence the outcome. Yes, you got it right: you don’t appear anymore.
Funnels also assume that content maps cleanly to stages, where blog posts improve awareness, comparison pages drive consideration, and pricing pages take the final step in the decision. But when we talk about AI-generated answers, the model doesn’t respect those boundaries. Why? Because it works differently. The model pulls fragments from wherever it finds the strongest signals, regardless of content format or original intent.
As a result, funnel-based reporting becomes misleading. High awareness visibility coexists with zero decision-stage presence, strong traffic metrics mask a total absence in AI-generated recommendations, and so on. Funnels no longer work because they report movement, while answer engines operate on resolution. Most importantly, funnels focus on user behavior, but LLM answers are shaped by model behavior.
Rather than moving down a funnel, the model is synthesizing an answer that may satisfy multiple stages at once. And what measuring LLM visibility through a linear lens misses is a place where inclusion actually happens — during the internal evaluation phase.
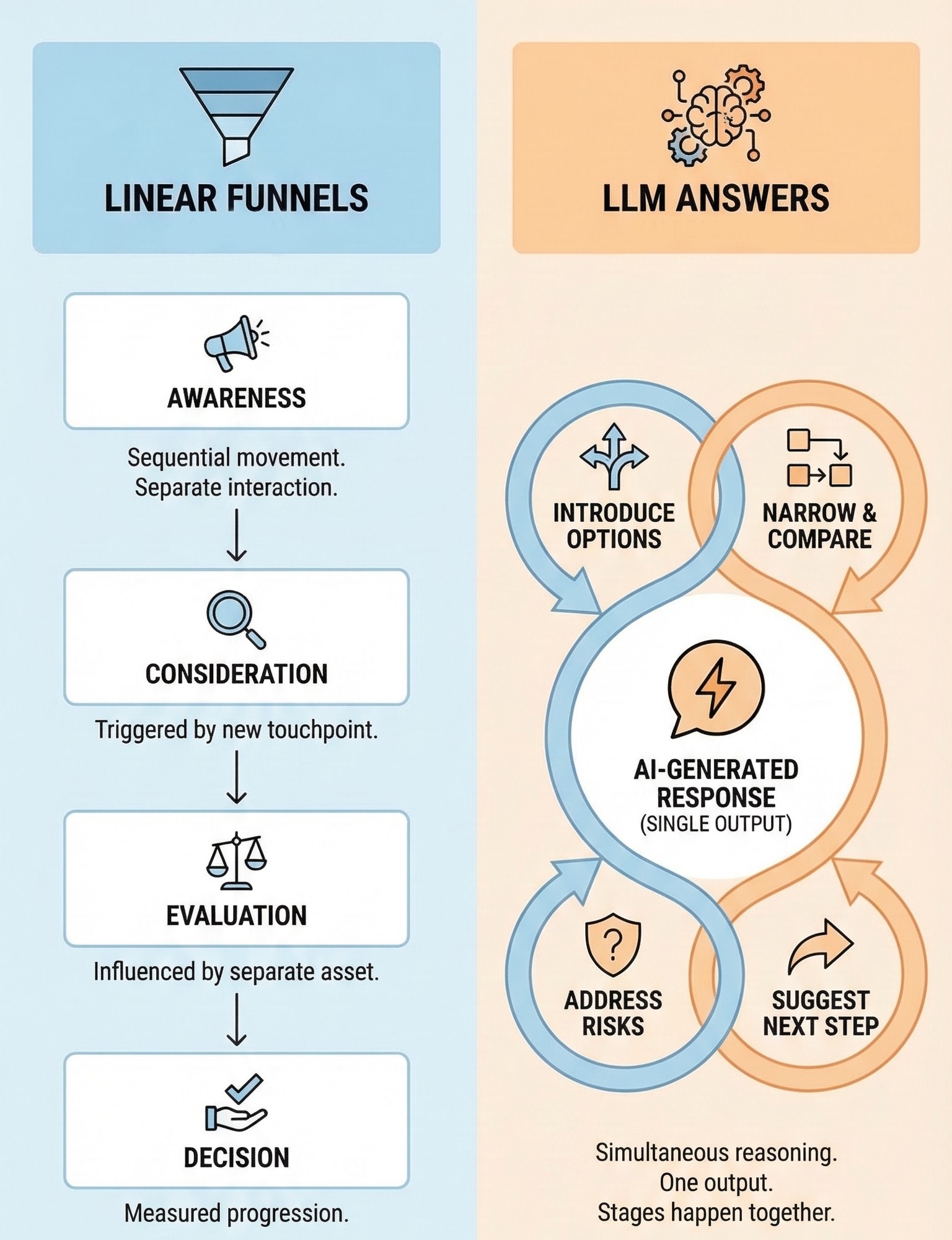
This is why LLM visibility tracking and GEO need a different grammar. And it’s not a funnel that assumes progression. It’s a stage model that reflects how decisions are reasoned inside the model. One that acknowledges overlap, loops, and compression — instead of pretending the journey is still linear. Once you accept that, the next step is to define the stages in a way that actually maps to AI reasoning.
Even though AI answers feel instantaneous, the reasoning behind them follows a consistent internal structure. LLMs don’t necessarily jump straight to conclusions. What they do instead is move through five decision stages that mirror how people actually evaluate options. These stages, compressed and resolved inside the answer, form the core journey grammar of AI search and GEO:
As we’ve already mentioned, these stages don’t appear sequentially on the screen. They operate inside the answer engine, often overlapping or looping within a short conversation or even a single response. However, they are always present in the model’s reasoning process. And this is precisely why GEO cannot rely on funnels or surface-level metrics: visibility only matters if it survives all five stages.
The next step is understanding how the model’s needs change across these stages, and why different types of signals are required at each one.
Although the five decision stages look quite familiar, what actually changes across them is not user intent alone — it’s what the model must be confident about in order to move forward. At each stage, the LLM is solving a different problem.
At the Explore stage, the model’s primary task is orientation. It needs to understand what class of solutions applies, what categories exist, and which approaches are relevant. Here, precision matters less than coverage. Missing a viable category at this stage narrows the journey prematurely.
In simple terms, the model is answering: What kinds of solutions exist, and what dimensions matter?
At the Narrow stage, the model shifts from coverage to fit. Constraints such as budget, scale, location, compatibility, or experience level start to eliminate options. The model must reconcile general possibilities with specific requirements.
In simple words, the model answers the following question: Which options still make sense given these constraints?
At the Compare stage, the model evaluates options against each other. This requires criteria: explicit or implicit dimensions that allow differentiation. The model must understand where options win, where they lose, and what tradeoffs are acceptable.
The question to answer is: How do these options differ in ways that matter for this decision?
At the Validate stage, the model focuses on risk resolution. It must address concerns that could block or reverse the decision: downsides, edge cases, hidden costs, reliability, and regret. Even strong options can be eliminated here if uncertainty isn’t resolved.
The model needs to focus on: What could go wrong, and is this still a safe choice?
At the Decide stage, the model compresses everything into a recommendation or next step. This requires sufficient confidence across all previous stages. If any unresolved doubt remains, the model simply ignores your brand.
Here, the question is: What should be chosen, and what happens next?
Understanding these shifting requirements explains why visibility behaves differently across stages: inclusion at Explore does not guarantee inclusion at Decide, strong differentiation at Compare can be undone by weak validation signals, and absence at Validate often matters more than absence earlier.
This is the foundation of stage-aware GEO: measuring not just whether you appear, but whether the model knows your brand well enough to confidently carry it through each stage.
Next, the focus shifts from the stages themselves to the answer assets and signals that support them. You will learn why “content” alone is no longer a sufficient way to think about influence.
One of the biggest mistakes teams make when adapting to AI discovery is trying to map content formats to stages just because it works in SEO and traditional funnels. That mental model no longer holds in the AI realm. What matters in the LLM era is not what you publish, but what the model can confidently use at each stage. Sounds a bit confusing, but let’s look at some details.
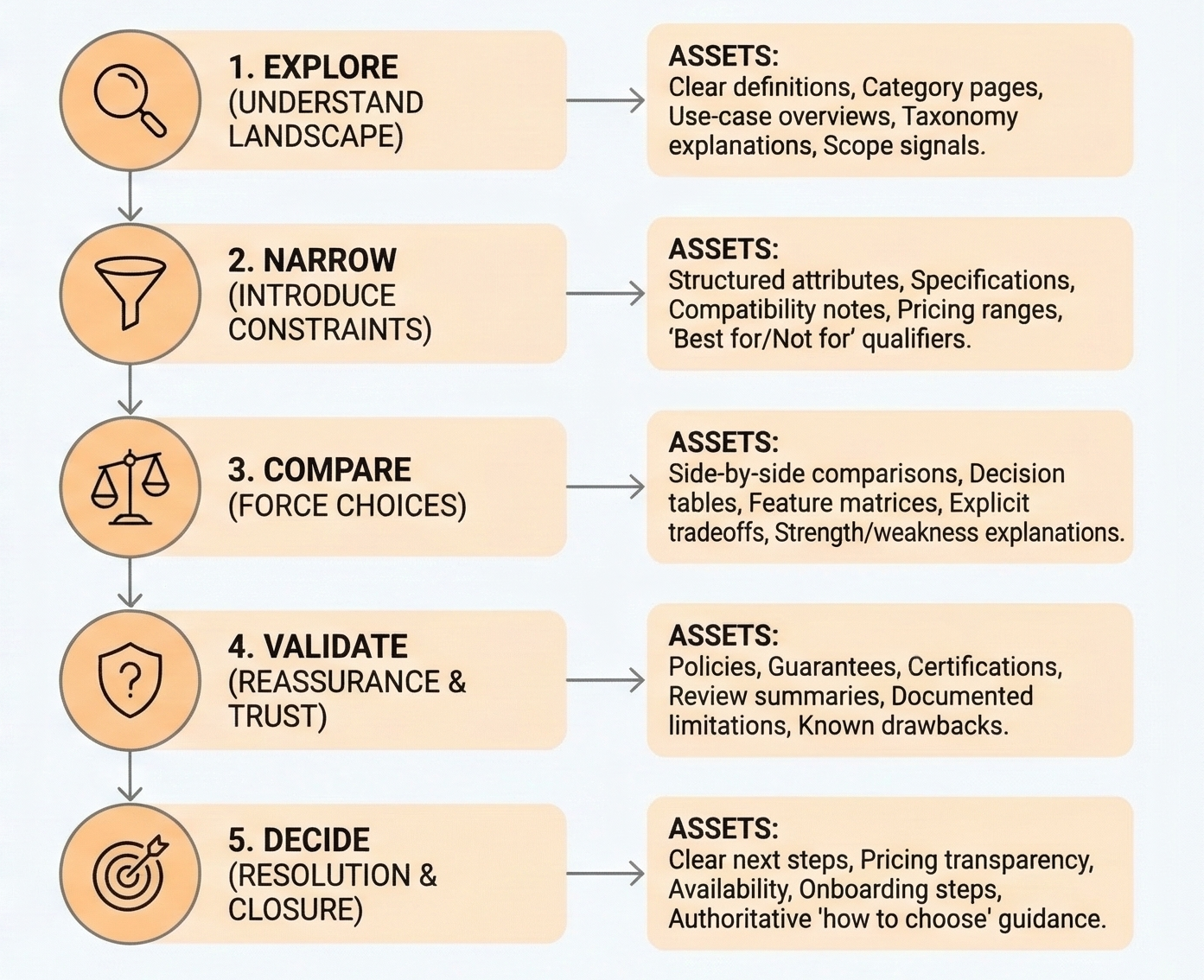
Seen this way, writing more content becomes the wrong abstraction. At least in GEO, because here, it is not about publishing more articles. It’s about ensuring that the right data and signals exist for the model to reason confidently at each stage. When your content is mapped this way, it turns into answer assets.
Once assets are aligned to stages, the remaining question is simple: Which stages are we actually present in — and where do we disappear? That’s where stage coverage measurement comes in.
Most brands don’t disappear everywhere; they disappear at specific stages. And stage coverage in LLM visibility measurement asks a simple but uncomfortable question: At which decision stages does the model confidently include our brand — and where does it stop?
And as we’ve already mentioned, presence at one stage does not imply presence at the next. A brand can appear frequently during exploration, yet vanish during comparison. Another may survive comparison, only to be excluded during validation when risk and trust enter the picture. Ignore stage-level measurement, and these failures will collapse into a single visibility score, where the reason for loss remains invisible.
To address this issue, stage coverage measurement separates the journey into components and evaluates inclusion per stage, not per query or per answer. Instead of asking “Are we visible?”, you ask:
When you accept this part of the LLM Visibility Journey Grammar, you can discover patterns that cause the problem. For instance, gaps at the Explore stage often signal category confusion or weak scope definition; drop-offs at Narrow suggest missing attributes or unclear fit; losses at Compare point to absent tradeoffs or weak differentiation; invisibility at Validate almost always traces back to trust, proof, or unresolved objections; and absence at Decide means the model cannot confidently route to an outcome.
These gaps are not content problems in isolation. They are reasoning failures from the model’s perspective. Something that it needs to move forward is missing or ambiguous.
Measuring stage coverage, in turn, turns visibility from a binary outcome into a diagnostic map. Instead of guessing why the model excluded you, you can see where the exclusion happened — and infer what kind of signal is missing. Seen this way, stage coverage is more actionable than aggregate visibility metrics. It tells you what to fix, not just that something is broken. And that’s the difference between knowing you lost and knowing where you lost the user inside the answer engine.
Although AI-generated answers feel instant, decisions inside them are not. Behind every generated response, LLMs still move through a recognizable AI discovery journey — exploring options, narrowing by constraints, comparing tradeoffs, validating risk, and finally resolving a choice. What has changed is not the journey itself, but its visibility. The messy middle is no longer spread across pages and clicks; it is compressed inside the answer engine.
This is why traditional funnels and surface-level metrics fail to explain LLM visibility. What comes instead is LLM Visibility Journey Grammar. With this powerful knowledge, you won’t be surprised that being mentioned once or appearing early does not guarantee influence. Visibility only matters if it survives the stages where decisions are actually made.
Journey grammar gives GEO a structure that matches how people actually buy in AI search. It shifts the focus from content formats to stage coverage, from generic presence to decision-stage inclusion, and from guessing to diagnosis. When you understand which stages the model can confidently reason through — and where it cannot — optimization becomes targeted instead of reactive.
If you want to apply this framework in practice, start with Genixly GEO. It is built with the LLM Visibility Journey Grammar in mind to help you track your brand presence across the decision stages of different models. Contact us now for more information. And don’t forget that in AI-driven discovery, influence is not about being everywhere. It’s about being present at the stages that decide. To learn more about LLM visibility measurement, follow this guide: How to Measure GEO Success.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

