.jpg)
Genixly team
-
November 26, 2025
AI in Ecommerce: A Guide to Today’s Gains & Tomorrow’s Trends
Lear more
Discover what conversation simulation is and how it can help reveal real LLM visibility across multi-turn buyer journeys. Learn how to measure GEO right.

Today, we are going to discuss conversation simulation, a method of LLM visibility measurement that evaluates how brands perform across multi-turn buyer journeys. Rather than testing whether a brand appears in a single AI-generated answer, conversation simulation offers a radically different approach. It observes how the brand is introduced, compared, questioned, and either chosen or replaced as the interaction progresses toward a decision. Why does this shift matter?
Well, the answer is quite simple: decisions inside LLMs do not happen at the first response. Instead, they emerge over follow-up questions, constraint tightening, comparisons, and validation — the same messy middle that defines real buying behavior. What happens when GEO relies only on prompt-level tracking?
It only measures awareness. At the same time, such important aspects of GEO as preference and conversion are ignored. Conversation simulation closes that gap by replaying realistic AI product discovery journeys. It exposes where brands actually win, where they quietly drop out, and which moments determine the outcome.
This guide explains why prompt-level tracking misses the decision moment, how LLM↔LLM simulation recreates real buyer pressure, which guardrails prevent biased results, and how to extract decision-grade signals such as replacements, sentiment drift, and conversion moments. By the end, you will understand how to measure GEO with conversation simulation, the way LLMs make choices. And don’t miss our Complete GEO Framework for more insights on LLM visibility measurement.
Let’s make it straight: prompt-level tracking is not useless or inefficient. It is simply limited. The only purpose of prompt-level tracking is to tell you that your brand appeared. And nothing more. It does not tell you what the model thinks about your brand or whether it would actually choose you. A useful analogy here is ecommerce:
Seeing traffic hitting your website may be a pleasant thing to watch, but it doesn’t necessarily mean revenue. Users may still compare alternatives, question trust, look for proof, hesitate over price, risk, or fit, and then abandon entirely. AI shopping workflow follows the same logic, just faster and more compressed.
From this perspective, a single prompt is equivalent to measuring store visits and declaring success. But in fact, you capture the moment of discovery rather than the moment of choice. In real buyer behavior — and in real LLM interactions — the decision happens after a series of events. It could be follow-up questions, constraint tightening, comparisons, validation, etc. Only then comes checkout. Prompt-level tracking, however, freezes the analysis before checkout. And that’s exactly why brands often look “visible” in screenshots yet disappear when the model is asked to compare, risk is introduced, pricing or constraints surface, or a final recommendation is requested.
It happens because prompt-level tracking measures visibility at the moment of exploration, then assumes influence carries forward. In practice, the opposite is the case. The real loss happens later during comparison, validation, and the final recommendation, where prompt-level tests provide no visibility at all.
Conversation simulation, however, exists to observe what happens between visibility and decision — the equivalent of watching the entire funnel, not just random people landing on your page. By replaying realistic buyer journeys turn by turn, it exposes where brands actually win, where they get replaced, and where decisions are resolved inside the model.
Without that lens, GEO remains stuck measuring awareness, while preference and conversion form deeper in the interaction. To observe what actually happens after the first answer, the measurement setup itself has to change. Let’s look at the details.
So, the very foremost thing you should know about conversation simulation is that it has nothing to do with creating more complicated inquiries or generating more answers. Its initial purpose is to reproduce the pressure of a real buyer journey. And that pressure cannot exist if the same system asks and answers its own questions.
In a real decision process, the person asking questions and the system providing answers (whether it is AI, a website, or a real seller) play fundamentally different roles. The buyer reacts to what they hear, and the seller responds, creating a sequence of events that navigate the buyer through tension, uncertainty, and narrowing choices. How to simulate this dynamic inside an LLM environment, you will ask? First of all, you must separate the roles between the two systems. It cannot be ChatGPT asking questions and ChatGPT answering them.
Thus, the target engine is the LLM whose behavior you want to measure. It is treated as a black box. It answers questions, introduces options, frames tradeoffs, and suggests next steps exactly as it would for a real user. The system running the test does not guide or correct its behavior. It only records what happens.
The user simulator, in its turn, exists to apply realistic pressure over time. It does not know which brand should win. It does not try to optimize outcomes. Its role is to continue the conversation the way a buyer would, by asking follow-up questions, introducing constraints, revisiting doubts, and pushing toward a decision when enough information has accumulated.
This separation matters because a single model cannot meaningfully challenge itself. When one LLM both asks and answers, it implicitly anticipates its own logic. This results in shallow comparisons and doubt resolved too quickly. In other words, the conversation converges toward a clean, internally consistent outcome that looks stable, but never reflects real buyer behavior.
Two interacting models, however, prevent that collapse. The simulator keeps probing based on what it hears, while the target engine continues responding without awareness of the testing goal. This back-and-forth is where instability, replacement, hesitation, and loss actually appear. But for that observation to be meaningful, the conversation simulation itself must not bias the outcome. The next step is ensuring that brands appear only when the model decides they belong — not because the test forced them in.
If conversation simulation is meant to reflect real buyer behavior, it must also remove one of the most common sources of measurement bias: brand injection.
Let’s suppose you are looking for a brand new pair of running shoes. You go to a preferred answer engine and start a conversation. How would your first message look?
“Please, help me choose a pair of running shoes…” Next, you provide constraints like budget, climate, type of workout, etc. What you won’t do is provide a real brand name. At least, at this point. That’s because in real AI-driven discovery, users start with a problem, a use case, or a constraint. Brands appear later — if the model believes they belong. Conversation simulation must preserve that dynamic; otherwise, the test stops measuring discovery and starts measuring recall.
This is why a core guardrail in GEO conversation simulation is simple but strict: the user simulator is not allowed to introduce brand names. Brands can only enter the conversation when the target engine introduces them on its own.
If you ignore this rule, the simulation becomes contaminated. Once a brand is mentioned explicitly, the model stops evaluating options and starts responding to a known entity. The result may look positive — the brand is discussed, compared, even recommended — but you have to deal with the forced visibility, not earned.
That distinction matters because LLM visibility monitoring is not about whether a model can talk about your brand when prompted. It is about whether it chooses to surface your brand when solving a buyer’s problem.
This guardrail also exposes a more uncomfortable truth. Many brands that look “visible” in prompt-level tests only appear when they are named. When brand mentions are removed, those same brands often vanish entirely. Unlike single-prompt tracking, conversation simulation makes that absence visible and measurable. By preventing brand injection, it preserves the integrity of the journey, allowing you to see:
In other words, this guardrail protects the difference between being known and being chosen. And once brand injection is removed, something important becomes visible almost immediately: buyer journeys do not move forward in a straight line.
When conversation simulation is allowed to run without forced brands, the interaction rarely follows a clean sequence from discovery to decision. Instead, it branches.
In simple words, the AI-based shopping journey happens as follows. A user asks an initial question. The model responds with options. The next question doesn’t simply “advance” the journey — it often loops back, reframes the problem, or introduces a new constraint that reshuffles the landscape entirely. This is the messy middle in action.
In practice, messy middle loops show up as:
Conversation simulation makes these loops visible because the user simulator reacts to the model’s answers rather than following a predefined script. If an answer introduces uncertainty, the next question reflects doubt. If an option looks promising but risky, the next turn probes risk. If tradeoffs surface, the journey branches. Thus, each branch represents a plausible buyer path, rather than an edge case.
What if you still believe in prompt-level tracking in LLM visibility measurement? Well, the branching behavior described above is exactly what prompt-level tracking cannot capture. A single prompt assumes intent is fixed. Real buyers, however, adjust intent continuously based on what they learn. LLMs respond to that adjustment — and in doing so, they replace, downgrade, or elevate brands across turns.
From a GEO perspective, this is where visibility becomes fragile. A brand may appear confidently in one branch and disappear entirely in another. Another brand may never appear early, but dominate later branches once constraints sharpen. There is no single “answer” here — only paths with different outcomes.
Conversation simulation does not try to collapse those paths into one result. It preserves them, tracks them, and measures where the brand survives, where it is replaced, and where it never re-enters the journey at all. In other words, conversation simulation helps understand what happens to the brand as an AI buyer journey evolves.
Conversation simulation produces value, and it is not in long dialogues. It is in exposing change over time. While each turn adds pressure and each follow-up forces the model to re-evaluate what it previously said, that re-evaluation is what truly matters. It is where the most important GEO signals live.
And one of the clearest signals is replacement. As constraints tighten or comparisons become explicit, the model often swaps options. A brand that appeared earlier may be removed entirely, replaced by another that better fits the refined criteria. But don’t make hasty conclusions: this replacement is not random — it reflects how the model understands category fit, tradeoffs, and relevance. And tracking who replaces whom, and under what conditions, reveals competitive dynamics that single prompts completely miss.
Another critical signal is sentiment drift. Early in a journey, brands are often framed neutrally or optimistically. As the conversation progresses, the framing can change because risks surface, limitations are mentioned, caveats accumulate, and so on. But sometimes the reverse happens: an initially marginal option becomes more positively framed as trust signals or proof emerge. Thus, sentiment drift is here to help you see whether the model’s confidence in a brand strengthens or erodes as it reasons forward.
Finally, there are conversion moments. These are turns where the model stops describing options and starts suggesting action: what to choose, where to buy, what to do next. Conversion moments are not guaranteed, and they don’t happen at a fixed time. When they do appear, however, they reveal who the model believes should win right now. Being present earlier but absent here is the GEO equivalent of abandoned checkout.
What is also important to remember is that a single extraction tells you nothing in isolation. What truly matters is how multiple extractions connect. For instance, a brand that appears early, survives replacement, maintains positive framing, and is still present at the conversion moment has real influence. And on the contrary, a brand that flickers in and out, or disappears just before action, does not, regardless of how visible it looked at the start.
With conversation simulation, you can turn these dynamics into measurable signals. Signals that show not just that you appeared, but how you were treated as the model moved from exploration to decision. And once you know what to extract from a simulated journey, the remaining question is practical: how do you run these simulations in a way that is realistic, repeatable, and decision-useful, without turning GEO into an endless research project?
Conversation simulation does not start with dozens of prompts. Neither does it start with fully scripted dialogues. Instead, it begins small and expands deliberately.
The entry point to every conversation simulation is a short list of seed prompts — typically five to ten — selected from the prompt universe you already validated earlier. Each seed here represents a realistic way a buyer might begin exploring a solution. Keep in mind that you have to avoid edge cases and optimized queries. The goal is to select seeds that can anchor the simulation in real demand rather than hypothetical coverage.
From each seed, the conversation unfolds over multiple turns. The simulator reacts to the target engine’s answers, introduces constraints, asks for clarification, compares options, and seeks reassurance. Over roughly twenty to thirty turns, the messy middle plays out naturally: branches form, loops appear, and paths diverge toward different outcomes.
You don’t need to ask every possible question. The purpose is to let the decision logic reveal itself. At this depth, patterns start to stabilize, so that you can see which brands survive refinement, which ones are consistently replaced, and where the model tends to resolve the journey. The output of this process is a summary report that collapses complexity into insight:
The infographic below shows a schematic illustration of a conversion simulation:
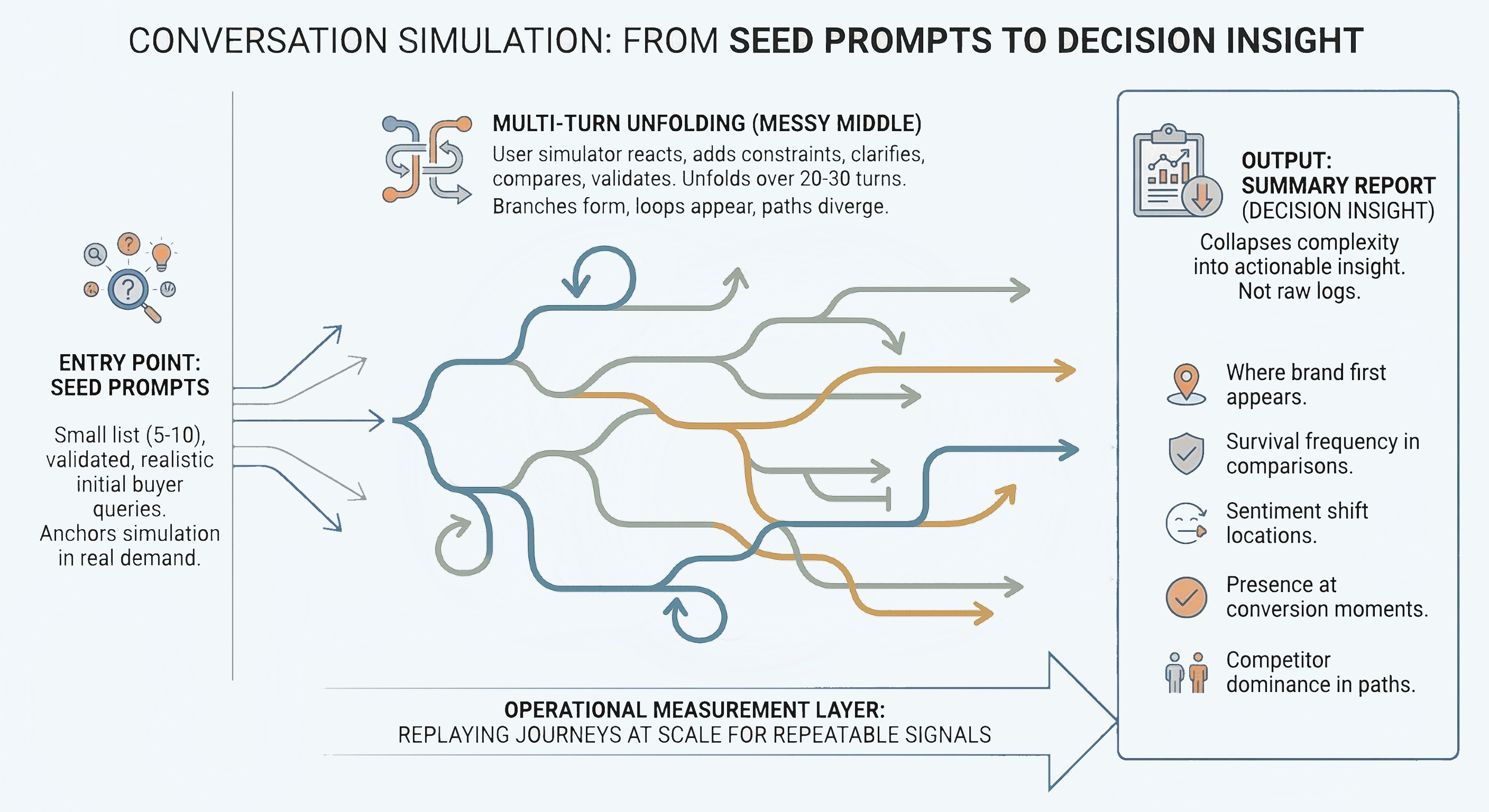
This structure keeps conversation simulation operational rather than exploratory. Instead of chatting with the model, it can help you replay buyer journeys at scale, extracting repeatable signals from them. Done this way, conversation simulation becomes a measurement layer rather than a research rabbit hole. As a result, you get inputs that can actually guide GEO decisions. Follow our Conversation-First GEO Measurement Guide to discover other key components to measure LLM visibility where decisions are made.
Conversation simulation exists because buyers don’t decide in one turn, and neither do LLMs. While single-prompt tracking can tell you whether a brand is visible somewhere in AI-generated answers, you will never know whether your brand survives comparison, withstands doubt, or remains present when the model is asked to choose. This gap is where most GEO strategies quietly fail. But it can be easily closed with a conversation simulation.
By simulating multi-turn journeys, you discover how options are introduced, how they are replaced, how sentiment shifts as constraints tighten, and who is still standing at the conversion moment. Instead of guessing based on isolated prompts, you observe decision logic unfolding over time.
This is also why conversation simulation is not an add-on to GEO — it is the layer that connects visibility to outcomes. It translates prompt reality and journey grammar into something decision-grade: which paths you win, which paths you lose, and why. If you are serious about LLM visibility, this is the moment where measurement stops being theoretical and starts reflecting how people actually buy.
Run your first simulated journey with Genixly and see how your brand performs when the model is pushed all the way to a decision — not just the intro. Contact us for more information.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

