.jpg)
Genixly team
-
March 25, 2026
Explaining Sentiment Drift in AI-Generated Answers: Why LLMs Develop Negative Framing and How to Reverse It
Lear more
Learn what replacement maps in GEO are, how they reveal competitors when your brand is absent in AI answers, why it happens, and how to fix LLM visibility.

One of the reasons why brands usually lose the competition in AI-driven discovery is that the model better understands a competitor, even if that competitor is not necessarily better than you. And this is the exact problem replacement maps solve.
A replacement map is a GEO competitive analysis method that shows which competitors appear in AI-generated answers under the same intent, constraints, and stage when your brand is absent. In simple words, they help you understand, who takes your slot and why when your brand disappears.
What about traditional competitive analysis, you will ask? Well, it can’t answer that complex question just because rankings assume stable lists and direct comparison. But answer engines were never meant to work that way. Because they assemble responses dynamically, filling contextual slots based on what the model believes fits best in the moment, traditional competitive analysis falls short.
In this article, we break that invisible process open. You’ll learn what replacement really means in answer engines, why replacement follows missing attributes rather than randomness, how to build a replacement map, and why segmentation by stage reveals entirely different competitive dynamics. We will also teach you how to act ethically in a replacement. And don't miss our Complete GEO Framework to learn more insights on LLM visibility measurement.
When comparing GEO to SEO, one thing stands out clearly: Unlike in SERPs, competitors in AI-generated answers win by appearing where you don’t, rather than by ranking higher. This distinction is the foundation of replacement analysis in GEO. So, let’s be a little bit more specific here.
Although the new realm may look quite sophisticated, things are pretty straightforward here. A replacement, for instance, occurs when an AI-generated answer surfaces another brand specifically because yours is absent under the same intent, constraints, and stage. The model, however, is not choosing against you. It is just filling a slot by selecting the entity that best fits the framing constructed in that moment.
Consider that there are two almost identical brands in the niche. One offers slightly better characteristics. However, the brand with the better characteristics doesn’t position itself clearly as the market leader. Existing customers do know the leader, but LLMs cannot understand it without clear positioning, always pointing to the competitor, which is objectively worse. And guess what? Traditional competitive metrics fail to reveal that because there is no fixed list, no stable ordering, and no universal “top result” under these new GEO circumstances.
What LLMs do instead is assemble an answer from what they believe belongs. If your brand does not meet the implied requirements of the prompt — whether those requirements are explicit or inferred — the slot is filled by your competitor that meets them. What if your website has tons of external backlinks and keywords? It no longer matters that much. And what’s even more unpleasant is that the actual quality of your products or services never directly impacts the selection.
Replacement is, therefore, contextual rather than adversarial. The competitor that appears instead of your brand is not necessarily better overall. They are simply the closest match to the attributes, proof, or positioning the model needs to complete the answer safely.
From a GEO standpoint, it means that you should reframe your approach to competition. First of all, remember that you are not fighting rivals directly anymore. In the realm of answer engines, you are at odds with yourself, competing with absence: missing data, unclear constraints, weak context signals, or insufficient grounding. That’s because the model does not “prefer” a competitor but defaults to them when your brand is not legible in that situation.
When you understand that, it’s essential to move forward. Next, you should find out what exactly prevents you from appearing in AI-generated answers.
Many brands still make the same mistake. When a competitor replaces you in an AI-generated answer, it can feel arbitrary at first sight. Because that’s how answer engines work: one day you appear; the next day, someone else does. But don’t let this misconception fool you.
If your brand does not constantly win the AI-led discovery in your niche, that’s because something is missing on your side. Therefore, you need to look across prompt families and repeated runs to detect a pattern.
In answer engines, replacement follows absence, not chance. Every slot here is implicitly defined by a set of requirements. While some of them are obvious, such as price range, use case, or scale, the others are inferred, such as trust, availability, risk tolerance, or category fit. If your brand fails to satisfy even one of these requirements clearly enough, the model does not hesitate. It substitutes an entity that does (your competitor).
Replacement happens when the model cannot confidently associate your brand with a specific attribute it needs to answer the prompt safely. That attribute might be factual, such as compatibility or pricing clarity. It might be contextual, such as “beginner-friendly” or “enterprise-grade.” Or it might be evidentiary, such as third-party validation or policy transparency. This is called the missing attribute pattern.
What makes this pattern useful for your competitive analysis is its consistency. If the same competitor tends to replace you in the same situations, across similar intents and stages, consider this repeatability a signal. The signal tells you that the model has learned a rule: when this condition appears, choose that entity instead.
It’s vital to mention here that this is not about who has “more features” or “better marketing.” It is about who satisfies the minimum legibility threshold for a given context. The competitor who replaces you is often not the strongest overall, but the safest answer when something is missing.
At this point, we come close to replacement maps. In the next section, you will learn how to discover why your brand is not visible in AI answers and which attribute gap causes the substitution.
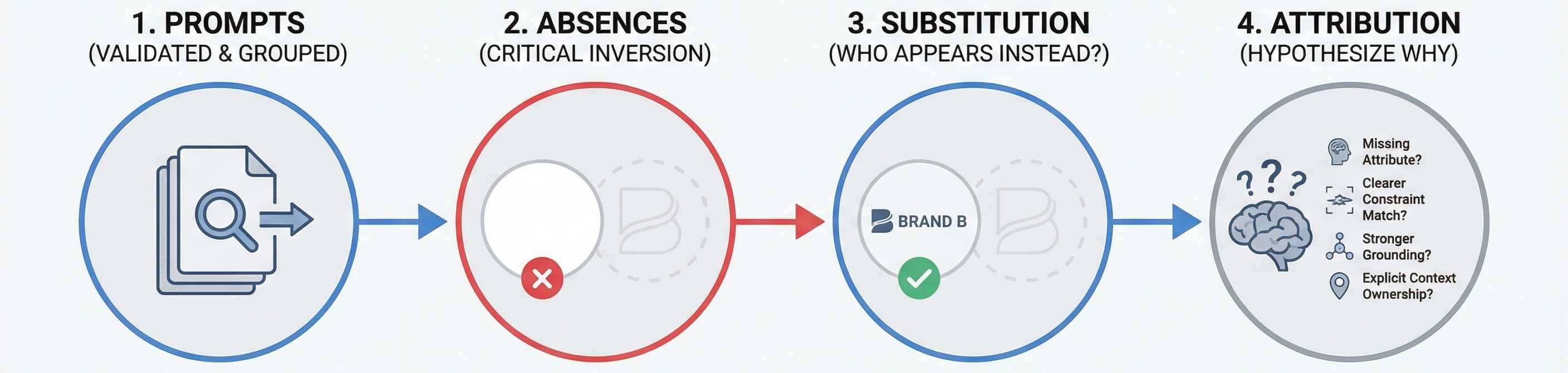
Although the next phrase may sound obvious, it’s important to say it out loud: You build a replacement map by following absence, not presence. Now, let’s proceed to the actual steps.
The process starts with prompts rather than competitors. You take validated prompt families — already grouped by intent and stage — and observe where your brand should reasonably appear. It’s extremely important to avoid speculative prompts and use the ones that represent real ways the model is asked to solve a problem associated with your brand, not naming the brand.
By doing so, you can identify absences. For each prompt family and stage, you mark runs and conversation paths where your brand does not appear at all. Note that this is the critical inversion most competitive analyses miss.
Only after the absence is established, you proceed to substitution. At this stage, you need to identify who appears instead of you. Learn which entities consistently fill the slot across similar prompts, repeated runs, and stages. Yet, consider that one-off appearances are noise. It results in evaluating the true replacement patterns under repetition. If the same competitor shows up whenever you disappear under the exact conditions, you’re looking at a genuine replacement relationship.
And here comes the final layer — attribution. At this stage, you assume why your brand is being replaced. The easiest way is to answer the following questions:
Later, you need to validate these hypotheses through targeted fixes and re-tests. But even at this stage, the map itself makes the pattern visible. And it is not a leaderboard. It is a cause-and-effect graph:
Once you see that structure, what happens to competitive analysis? Right, it stops being reactive, meaning that you no longer need to chase competitors. What you need instead is to close the gaps that invite them in.
Considering the fact that AI-driven discovery lives across different stages, it becomes evident that not all replacements matter equally. In answer engines, replacement behavior changes by stage, because the model is solving a different problem at each point in the journey. Therefore, treating them as one bucket is a mistake.
At the Explore stage, for instance, replacements are usually broad and permissive. The model is mapping the landscape, so it favors entities that act as category anchors: well-known names, general-purpose options, or brands with wide contextual coverage. If you’re replaced here, it often signals weak category association or insufficient co-mention presence. The loss is about recognition, not trust.
At the Decide stage, on the contrary, replacements are narrower and more consequential. The model is no longer exploring — it is committing. Here, replacements are driven by clarity and safety: pricing transparency, policies, availability, risk reversal, and grounding in trusted sources. Being replaced at this stage means the model did not feel confident recommending you when the cost of being wrong was highest.
The difference matters because the same competitor can replace you for entirely different reasons depending on the stage. Below is a stage-by-stage replacement framework that connects where replacement happens to why it happens — and how to resolve it.
In GEO, knowing where you are replaced is often more actionable than knowing by whom. And to address that, you need a framework that we provide below. But before going any further, check other insights here: Competitive Intelligence for GEO.
Now, we’ve finally come to the point where replacement maps become not only useful but also actionable. At this stage, they lead to ethical slot capture, improving your fit for a slot without manipulating prompts, sources, or models. In GEO, most replacement patterns point to one of three gaps we discuss below:
In answer engines, ambiguity is a liability. When a model has to guess whether your brand fits a constraint, it usually won’t, replacing you with an option that is easier to reason about.
Data-driven slot capture comes into play here, removing inference from the equation. You need to expose the attributes the model implicitly looks for when assembling an answer: pricing ranges, supported use cases, exclusions, compatibility, availability, geography, scale limits, and operational constraints. Importantly, this is not about adding more content. It’s about making decision-critical data explicit, structured, and comparable.
Your brand may disappear not because it lacks features, but because those features are buried, scattered, or framed narratively instead of declaratively. Clear tables, “best for / not for” sections, constraint summaries, and attribute lists reduce replacement risk by making your fit obvious at retrieval time.
If the model can confidently answer “Does this meet the requirement?” without hedging, the slot is far less likely to be filled by someone else.
What happens when the cost of being wrong increases? The model has no other option than to become conservative. This is where proof, not persuasion, determines replacement.
Proof anchoring means supplying evidence that the model can reuse without risk: third-party reviews, authoritative lists, certifications, benchmarks, documented outcomes, transparent policies, and neutral comparisons. If you think these assets don’t need to be glowing, we have some good news — they only need to be specific, verifiable, and repeatable.
For instance, a common replacement pattern at the Compare and Decide stages is that competitors don’t just claim superiority — they are grounded elsewhere. The model routes to what it can justify. Ethical slot capture here means building a source layer that supports recommendations and avoids speculation.
Another essential improvement that proof anchoring introduces is that it also addresses sentiment drift. When evidence is present, the model relies less on vague caveats and soft warnings. Over time, this reduces volatility and drift, making your presence harder to dislodge.
If you position your product as a one-size-fits-all solution, you are doing it wrong. At least from the perspective of GEO and LLM visibility. Many brands are replaced in AI-assisted shopping because they try to be everything. In AI answers, however, broad positioning creates uncertainty, which, in turn, invites substitution.
That’s because positioning in GEO is not messaging; it is constraint resolution. You win slots by clearly signaling where you are the right answer and, just as importantly, where you are not. This includes context tags like budget vs premium, beginner vs enterprise, niche vs generalist, but expressed through concrete trade-offs, not slogans.
Competitors often replace you simply because they make the choice easier by narrowing the decision space, articulating trade-offs, and, as a result, reducing the model’s cognitive load. Ethical slot capture through positioning means embracing specificity: publishing comparisons, clarifying limits, and making your win conditions explicit. When positioning is precise, replacement becomes unnecessary. The model doesn’t need an alternative, because the slot is already filled with confidence.
Together, data clarity, proof anchoring, and positioning precision form the ethical path to slot capture. They don’t manipulate the system. They align with how answer engines reason and remove the gaps that make replacement inevitable. To learn more about how to create content that perfectly aligns with answer engines, read these guides:
As you’ve just seen, competitive loss rarely looks like defeat in answer engines. What it looks like is silence or emptiness, fulfilled by someone else taking your place. With replacement maps up the sleeve, however, you can make that silence visible, explainable, and fixable.
Replacement is neither random nor personal. It is structural. When your brand disappears from an AI-generated answer, the model is solving a problem with incomplete information. Therefore, a competitor appears not because they are universally better, but simply because they satisfy a missing requirement more clearly than you do. Replacement maps turn that invisible decision logic into something you can analyze and act on.
By grounding competitive analysis in prompt families, stages, and absences, replacement maps move GEO beyond surface-level comparisons. They show where you are replaced, by whom, and why. More importantly, they point directly to ethical action paths — clearer data, stronger proof, and more precise positioning — that allow you to reclaim the slot without guessing or gaming the system.
This is the shift that matters in GEO competitive analysis. You stop reacting to competitors and start resolving the gaps that invite them in. When those gaps are closed, replacement stops being attractive because the model no longer needs an alternative.
If you’re ready to scale beyond manual analysis and automate your GEO replacement maps management, drop us a message — we know how to enhance your GEO strategy with AI.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

