
Genixly team
-
April 9, 2026
Co‑Mention Networks in GEO Explained: Your Guide to Shaping AI Category Memory
Lear more
Learn how the wet сement strategy in GEO helps shape AI category memory early — influence defaults, reduce volatility, and win before retrieval patterns harden.

Since LLMs need time to learn, AI categories aren’t something that forms overnight. Like cement, they need some time to harden. Therefore, we call the period before they become solid the wet cement phase. During it, a niche is new, definitions are unstable, comparisons are inconsistent, and no single brand clearly dominates retrieval. Large language models are still “learning” how to structure the space through repeated exposure to definitions, datasets, and third-party references.
Unfortunately, most teams never take this nuance into account and focus on LLM visibility only after patterns stabilize, when semantic defaults are already set. The same brands appear in Explore prompts, survive Narrow constraints, and dominate Compare and Decide stages. And breaking into a hardened category requires displacement, which is far harder than shaping it early.
The wet cement strategy in GEO, however, offers a different approach. Instead of fighting entrenched retrieval logic, you influence it while it’s still forming. In this guide, you’ll learn how to do that. We explain why early narratives become default truths, what to publish when cement is still wet, how to become the semantic default in your niche, how to measure category hardening, and what to do once defaults are set. For more insights on how to improve your LLM visibility, go straight to our Complete GEO Framework.
While it seems that early narratives won’t hurt your brand's appearance in AI-generated answers, the chilling truth is the opposite.

When a niche is new, terminology is unstable, comparisons are sparse, and few canonical sources exist, the first structured definitions, datasets, and comparisons that enter the ecosystem often become the reference points models rely on later. This is what we call the wet cement moment in GEO. It describes the period before a category “hardens” into stable retrieval patterns. During this phase, AI memory shaping is fluid because the model’s understanding of what the category is, who belongs in it, and how brands differ is still forming. What does it mean for you as a brand?
Over time, this repetition solidifies, leading to the same brands appearing in the same contexts, the same comparisons being reused, the same definitions being echoed, etc. What started as a single interpretation becomes a semantic baseline that later shapes retrieval logic. Consequently, when a user asks about the category, the model pulls from the hardened narrative.
This is why the early adopter benefit in GEO is not about traffic spikes. It’s about influencing the initial structure of the AI category memory. Once that structure stabilizes, entering later requires displacing entrenched associations — a far harder task than shaping them when the cement was still wet.
Now, let’s explore what you need to publish when the cement is wet. As you might have already guessed, we are not going to discuss a good marketing copy below. Instead, you will find three types of assets, or structural content, that influence LLM visibility the most in both the short and long run when AI memory shaping is still fluid.
During the wet cement stage, models crave for materials that help stabilize understanding. These include clear definitions, data-backed claims, and standardized comparisons. If you publish such materials early, you significantly increase the probability that your framing becomes the baseline retrieval logic for the category your brand belongs to. Let’s be more specific on each asset:
When AI memory shaping starts, your number one goal is to define the category clearly and repeatedly. Please note that marketing language is the last tool you need to use here. But don’t get us wrong: we are not against a good marketing copy. However, from the AI standpoint, it is often useless because models require structured content based on neutral terms.
You need to define the category your brand belongs to, clearly explain what problems it solves (and, what’s also important, what problems it seems your brand might solve but it doesn’t), and describe what distinguishes it from adjacent categories.
If you are the first to implement specific definitions and they get reused across blogs, glossaries, and third-party explanations, we have some good news: they may become semantic anchors. If your framing is adopted early, the model will repeatedly associate your terminology with the category itself.
As a result, your brand is not cited because it fits a specific category; it is cited because it creates the category itself. And, the model is way more confident in it than in your competitors that fit into the category you created.
Since models rely heavily on comparative structure, publishing benchmarks, performance metrics, pricing ranges, or adoption statistics provides LLMs with something measurable to reference.
Even simple comparative datasets are essential for your GEO during the web cement stage because they can serve as default reference points if nothing else exists yet. Over time, those data points become embedded in lists, summaries, and review narratives that the model operates with.
Side-by-side breakdowns of approaches, alternatives, or trade-offs introduce another asset type that is especially powerful in the early stages of LLM visibility strategy. When a category yet lacks standard comparison criteria, the first structured matrix often defines what “matters.”
In practice, this looks as follows: You publish an “X vs Y vs Z” comparison in a new niche, it gets widely cited, and that defines the evaluation framework. As for later entrants, they must argue within the structure you introduced.
It is important to note here that if your competitors don’t introduce anything semantically new, the model ignores them. So they either need to offer an alternative view or the notably extended version of the original comparison.
For all three types of assets, the key principle is simple: when cement is wet, clarity compounds. Publish structural content that others can cite, summarize, and replicate. Thus, you increase the chance that your framing hardens into the category’s semantic default.
Although publishing early is great, it is not enough to become the semantic default. To achieve this number one goal, your framing must be repeated, reused, and reinforced across contexts until the model treats it as the natural starting point. Here are 4 GEO tactics to shape AI memory during the wet cement stage:
To learn more about how to create content that perfectly aligns with answer engines, read these guides:
Over time, the 4 AI memory shaping tactics reduce variance. Consequently, your brand begins to appear predictably across prompt families and conversation paths because the model no longer questions its category placement. It understands that your brand itself is the category.
You don’t need to guess whether your wet cement GEO strategy went well. What you need instead is to measure the hardening. Below, we explain how to prove it by tracking stability over time and reduced variance.
Follow these steps to measure stability over time in LLM visibility for your GEO campaign:
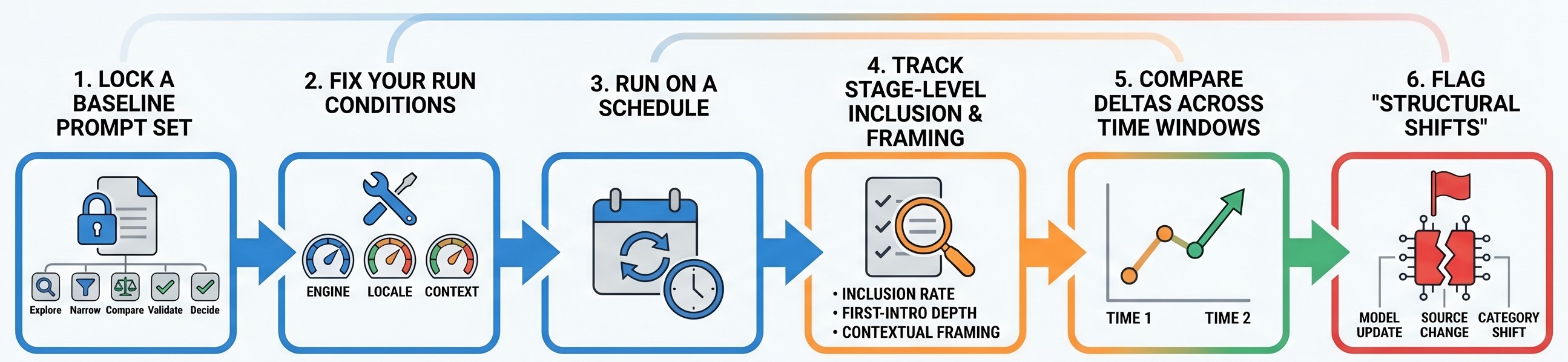
Now, let’s talk about reduced variance in AI-generated answers. Here is how to measure it for your wet cement strategy GEO campaign:

Together, these two measurements tell you a lot about what models think about your brand during the wet cement stage and after the hardening. Stability over time shows whether category memory is solidifying. Reduced variance shows whether retrieval behavior is becoming predictable. When both tighten, the niche is hardening, and late entry becomes harder but not impossible.
Once the cement hardens, the rules change because retrieval patterns stabilize, category definitions solidify, and the same brands appear predictably across prompt families. You are no longer shaping the narrative — you are competing inside it. Therefore, you should shift the strategy from influence to displacement, and these are the 6 steps to follow at this stage:
Identify which brands consistently dominate the Explore, Compare, and Decide stages. These are the semantic defaults. The dangerous path is to assume you can “out-publish” them. What you need instead is to analyze why they survive: due to context ownership, citation grounding, proof density, or category anchors.
Since you cannot win by rephrasing the same arguments, it is necessary to look for underserved contexts, missing constraints, or evaluation criteria that the hardened narrative ignores. Your displacement strategy requires introducing a new axis of comparison, because arguing inside the old one won’t let you improve your LLM visibility.
Early-stage broad prompts are hardest to penetrate once hardened. Instead, you must focus on high-specificity Narrow and Validate prompts where entrenched brands may lack clarity or proof. Winning these micro-contexts can help you create new retrieval footholds.
In hardened categories, Source Layer dominance becomes critical. If competitors are repeatedly grounded by trusted lists and reviews, your priority shifts to earning inclusion in those same sources or introducing new authoritative references that the model adopts.
In stable environments, volatility becomes your advantage. If your brand shows up inconsistently but with strong contextual fit, tightening that consistency can shift the balance. Remember that a predictable presence across runs can increase the probability of path wins in the long run.
Sometimes, the smarter move is not to fight inside the hardened category at all. If the core narrative is locked, consider defining a subcategory or adjacent framing where the cement is still wet. Shifting the frame can reset retrieval logic.
As you can see, hardening doesn’t mean you’re too late. It means the playing field is different. Instead of guessing, you can now see which defaults dominate, which contexts are closed, and where leverage still exists. The key to a successful GEO strategy here is to stop behaving like you’re early and start acting strategically inside a stabilized system. Follow our guide to Competitive Intelligence to learn more about how to take control over LLM visibility beyond the Wet Cement Strategy in GEO.
In AI-driven discovery, timing is everything. When a category is new, retrieval logic is still forming. You deal with unstable definition, inconsistent comparisons, fluid context tags, and so on. We call this moment the wet cement stage, and it is the only time when shaping AI category memory is easier than fighting it.
Once cement hardens, defaults emerge with the same brands, evaluation criteria, and sources appearing across stages and grounding recommendations. At that point, you are no longer shaping the narrative — you are competing against it.
That’s why your wet cement strategy in GEO is all about publishing the right structural assets early: canonical definitions, reusable datasets, and comparison frameworks that others adopt. You are influencing the semantic baseline before retrieval patterns stabilize and variance drops.
If you want a structured way to plan this timing advantage, identify emerging categories, define the assets that shape them, and prioritize publication before defaults set. Contact us now to learn how we can help you automate and simplify these processes.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

