
Genixly team
-
November 26, 2025
What Is a Personalization Engine? The Core Technology Behind Modern Engagement Explained
Lear more
Learn how to measure answer volatility and LLM noise/stability using prompt families, repeat runs, and distributions instead of unreliable snapshots.

LLM answer volatility is the first thing you notice when you start testing your brand’s visibility in AI-generated answers. And if it’s usually where frustration begins, you’ve come to the right place today.
You run the same prompt twice, and the output changes. Your brand appears, disappears, moves around, or gets framed differently. However, what looks like inconsistency at first glance is actually a core property of how LLMs operate. So, we must assure you that answer volatility is not a bug. It is how answer engines generate relevance in real time.
In the article that follows, we explain the importance of answer volatility for LLM visibility measurement (don’t forget to visit our Complete GEO Framework for more insights on LLM visibility). The guide will introduce you to the LLM Noise/Stability Index — a framework for measuring visibility in an environment where stability does not mean identical answers. You’ll learn how volatility can be used as a diagnostic signal, how to distinguish natural model variance from avoidable entity confusion, and how to measure GEO performance using prompt families and repeat runs instead of screenshots and ranks. But first things first: let’s unpack why volatility exists in LLMs.
Let’s make it straight: if you run the same prompt twice and get two different answers, nothing is broken. The variation you witness is a design property of LLMs rather than a defect in the system. Consequently, the worst thing you can do is treat volatility as an error to eliminate. It is the fastest way to misunderstand how AI-generated answers actually work. And looking ahead, we have to say that the second worst thing is to ignore volatility. Let’s see why.
What is an LLM response? Since it is not a fixed lookup, we considered it a generated artifact, assembled in real time from multiple moving parts. What happens if you change any one of those parts — even slightly? The output shifts. Sometimes it shifts subtly. Sometimes it alters dramatically, changing which brands appear, how early they appear, or how they are framed. The very nature of LLMs dictates answer volatility. But let’s look a bit deeper.
Answer engines are tightly associated with randomness in sampling. It’s when the model selects words in a non-deterministic way. Even if you stick to identical prompts, internal probability distributions produce variation in phrasing, ordering, and emphasis.
Retrieval adds another layer: different runs may surface different sources, knowledge chunks, or structured elements before the final answer is composed.
And don’t forget about personalization that further fragments outputs by location, language, or session context.
The last piece of the puzzle is formatting logic. It reshapes how the same information is presented. We mean randomness in generating an answer as a list or in a few paragraphs, as a summary, or in a comparison, etc. None of this is accidental because:
Why are all these things important from a GEO perspective? Because teams simply get them wrong, treating LLM answer volatility as noise to be smoothed away, averaged out, or ignored. Single-run snapshots are taken as truth (please, follow this link immediately if you still do so: The Single‑Prompt Lie: Why Your LLM Visibility Screenshot Is Not Data), and instability is blamed on the model being “unreliable.” In reality, volatility is nothing less than information that shares in-depth insights on how well models understand your brand:
So, in the first case, we deal with accidental inclusion. In the second, we face structural inclusion. Once you accept this nature of things, your LLM visibility measurement changes forever. You stop asking “Did we rank?” and start questioning across how many realistic answers your brand actually appears, and how stable this inclusion is. But what is stability from the perspective of answer volatility in LLM visibility tracking?
From the standpoint of LLM visibility measurement, stability never looks as most people imagine it. And that misunderstanding leads to chasing the wrong signals. Let’s stick to a simple but quite illustrative allegory.
Imagine a sunny day at the end of February somewhere in the Continental European climate when the temperature suddenly reaches +16°C. It feels like spring: people go outside without jackets, cafés open their terraces, and for a moment it seems as if winter is already over. If you look only at that day, you may conclude that February is a warm month. But it isn’t.
Step back and look at the previous weeks of cold and gloomy weather. The average temperature was about 3°C, most days were cold and rainy, and winter conditions clearly dominated. The only warm day didn’t change the season — it was a short-lived deviation inside a much colder pattern.
Now zoom out even further. From the perspective of ten years, that single +16°C day barely registers. It becomes an anomaly — a statistical outlier that explains nothing about the climate. It neither predicts future Februaries nor does it justify planning spring activities in winter. Answer volatility in LLM visibility tracking behaves the same way.
A single strong appearance in one AI-generated answer may feel decisive in the moment. But when viewed across many runs, many prompts, and long enough observation windows, it may turn out to be a rare spike inside an otherwise unstable pattern. Stability? It only emerges when visibility holds across time and variation. Anything else is just an anomaly.
Stability, however, does not mean getting the same answer every time. It does not mean identical wording, lists, and structures, or a fixed “rank” that never changes. Expecting that kind of consistency from a model is like expecting two people in different conversations to use the same phrases in the same sequence. That’s not how LLMs work.
From the standpoint of LLM answer volatility, stability is nothing more than pattern consistency under variation. It means that across different runs, prompt variants, and small contextual changes, the model behaves in broadly the same way with respect to your brand. In practice, it looks as follows:
If those patterns hold, visibility is stable, even if the model changes the exact phrasing of the answer every time.
Now, when you understand how to treat stability in AI-generated answers, let’s focus one more time on what it doesn’t mean. In short, it is the absence of volatility. LLM answer volatility will always exist. The question is only whether that volatility changes the outcome in meaningful ways. If your brand remains present across realistic answers, treat variation as cosmetic. If small changes make you disappear, well, we have some bad news for you: variation becomes decisive.
This distinction matters because many GEO metrics reward the wrong behavior. They treat a single strong appearance as success and ignore the fact that the next 99% of runs tell a completely different story. In other words, they consider the warm February day as an indicator of the climate rather than an anomaly. That creates a false sense of certainty.
Stable inclusion, however, is boring by design. It never spikes dramatically. Neither does it make for impressive screenshots. But it’s what actually survives real-world usage, where prompts are phrased differently, conversations branch, and answers are regenerated continuously. Understanding this is what allows GEO measurement to move from anecdote to signal. And this move is impossible without prompt families.
If volatility is expected, you cannot measure stable inclusion in AI-generated answers at the level of a single prompt. Neither a randomly generated list of prompts is suitable for that. Instead, you should use prompt families.
A prompt family groups together multiple prompts that express the same underlying intent, but differ in wording, structure, constraints, or emphasis. And rather than treating each phrasing as a separate signal, you analyze them as one analytical unit.
From a stability perspective, this shift is critical due to the fact that individual prompts are inherently fragile. Because small linguistic changes can alter retrieval paths, formatting choices, or emphasis in the model’s response, measuring visibility this way confuses phrasing sensitivity with actual relevance.
Prompt families, in turn, absorb that variability and reveal what really matters: whether the model consistently associates your brand with a given intent. In practice, prompt families do a different job than isolated prompts. Instead of monitoring your brand’s visibility for a particular wording, they switch the focus to the intent, regardless of how it is phrased.
This is exactly why prompt families are the smallest meaningful unit for LLM stability measurement. When a brand appears across most variants in a family, visibility becomes structural. When it appears in one variant and disappears in others, it is accidental. Seen this way, prompt families expose LLM answer volatility correctly.
However, there is still one problem unsolved: if asking the same question may produce different outputs, how many runs are enough to reveal the true visibility?
Unfortunately, there is no magic number of runs to measure LLM answer volatility that guarantees certainty. But there is a minimum threshold below which any claim about LLM visibility is simply not honest.
At that point, you are still looking at weather, not climate.
In practice, repeat runs are not about averaging results into a false sense of precision. Their purpose is to expose variance. This is a useful rule to follow:
What matters more than the absolute number is how you work with the results. Let’s suppose inclusion appears once and disappears four more times. In this case, running more tests will only add more confidence that your brand does not appear in AI-generated answers.
And this is precisely why repeat runs must be paired with prompt families: running the same phrasing ten times tells you less than running several realistic variants a few times each. Variety introduced in prompt families exposes sensitivity, and repetition reveals randomness. Mixed together, they offer a perfect formula for performing an honest measurement. As a result, you achieve enough evidence to say with credibility whether visibility is real or whether you are looking at an anomaly that will never survive contact with real users.
The next step after you reveal volatility is to understand what causes it. At this point, you should keep in mind that not all volatility is created equal. Some variation is intrinsic to how LLMs work.
As we’ve mentioned above, randomness, retrieval shifts, personalization, and formatting differences will always introduce movement in outputs. That kind of volatility is structural. It exists even when everything on your side is done correctly.
But there is another kind of answer volatility that is far more dangerous: the kind you cause yourself. This happens when the model is uncertain about what your entity actually is. This volatility is caused by entity confusion. Let’s say a few more words about it.
Entity confusion arises when a brand, product, or service lacks clear, consistent signals. Everything may go wrong: names are ambiguous, categories overlap, attributes are incomplete or contradictory, use cases are implied rather than stated, and so on. As a result, the model’s internal representation of the entity becomes unstable.
When that happens, even the smallest changes in phrasing can push the model toward different interpretations, so that in one run your brand fits the context, but in the next — it doesn’t because LLM simply doesn’t know where to place you. How to recognize this entity-driven? Look for these patterns:
This is different from natural model variance, which tends to preserve overall framing even when surface details change.
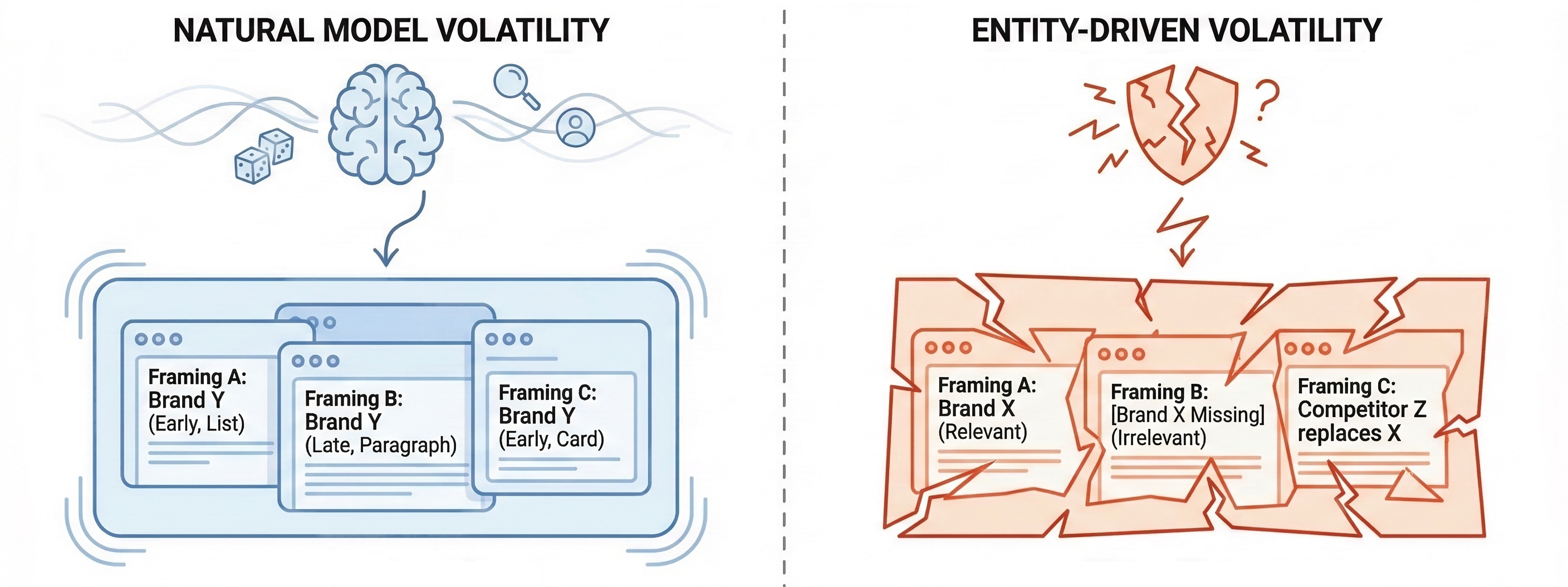
When volatility is caused by the model’s nature, distributions stabilize with enough runs. When volatility is caused by entity confusion, distributions remain chaotic despite the number of runs until the underlying signals are corrected.
Thus, one of the essential GEO goals is to eliminate avoidable volatility — the kind that exists because the model doesn’t clearly understand who you are, what you offer, or when you belong in the answer. Once that line is clear, your LLM visibility measurement becomes meaningful, providing a foundation for optimization.
Let’s now explore the actions to take when volatility is revealed. The good news is that high volatility is not a failure condition. Consider it a diagnostic state. And as in the case of any diagnostic state, it means that you can (and you must) act.
When visibility fluctuates sharply across runs and prompt families, the worst response is to dismiss the data or keep collecting more of it without changing anything. The first step is measurement discipline. Remember, you should confirm high variance before taking any actions across:
If volatility persists under those conditions, the signal is real. At that point, the task shifts from observing instability to locating its source. This is where a Volatility Audit Sheet becomes essential.
Here is how to use this sheet:
High volatility usually points to one of three problems:
To address these issues, read the following guides where we describe how to create GEO-friendly content:
Finally, volatility must be retested, not assumed resolved. The same prompt families and repeat runs are used again, with explicit before/after notes. The goal is not to eliminate all variance, but to reduce fragile visibility and increase stable inclusion across contexts. When handled this way, volatility stops being frustrating. It becomes a feedback loop that, in its simplest form, looks as follows:
That loop is how GEO moves from observation to control — and how high variance turns into actionable insight instead of anxiety. Follow our Guide to Complete GEO Framework for more detailed insights.
Rather than operate on fixed outputs, LLMs operate on probabilities. When visibility shifts across runs, prompts, and contexts, it is not exposing chaos. It is exposing how fragile or how structural your presence in AI-generated answers really is. Stability, in this environment, is not about sameness. It is about consistency under variation.
From that standpoint, LLM answer volatility is uncomfortable, not because it may look frightening, but because it breaks familiar mental models. It refuses to give you a clean rank, a stable screenshot, or a single number you can point to and move on. But that discomfort is a new factor that motivates brands to move further, delivering a better experience. And that’s exactly why answer volatility matters.
Once you stop trying to suppress volatility, GEO measurement becomes clearer: prompt families replace isolated queries, repeat runs replace one-off checks, and distributions replace rankings. What emerges is not noise, but a pattern you can trust, learning where you appear and, what’s even more important, how often and in which decision contexts you hold or lose ground.
Most importantly, volatility tells you what to fix. It shows where entity signals break down, where decision-stage data is missing, and where competitors are winning not by chance, but by clarity. And finally, it turns measurement into a feedback loop instead of a performance report. Want to automate this process? Start tracking distributions (not snapshots) with Genixly and automate your GEO workflow. Contact us now for more information.
Because LLMs generate responses probabilistically, pulling from different sources, contexts, and formatting logic on each run.
No. Volatility is a structural property of LLMs, not a malfunction. The mistake is treating a single output as truth.
Stability means consistent inclusion and framing across many runs and prompt variants — not identical answers.
If your brand appears consistently across prompt families and repeated runs, visibility is stable. One-off appearances indicate luck.
Usually 3–5 runs per prompt variant are enough to expose whether visibility holds or collapses.
It can come from natural model variation or from unclear entity signals, missing attributes, or weak positioning.
If volatility persists across runs and prompt families, it’s likely caused by entity confusion or missing signals rather than randomness.
Rankings assume fixed positions. LLMs produce distributions, not ranks, making position probabilistic rather than absolute.
No. You should measure it, understand it, and reduce avoidable volatility by improving clarity and alignment.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

