
Genixly team
-
November 26, 2025
What Is a Forward Deployed Engineer? The Rise of FDEs in AI, Enterprise Software, and Ecommerce
Lear more
Learn what sentiment drift in AI-generated answers is, how it causes negative framing in GEO, why it hurts conversion, and how to fix sentiment reversal.
.jpg)
Today, we will explore sentiment drift in AI-generated answers. It is one of the most underestimated and damaging risks in LLM visibility, because brands don’t just appear or disappear in the model’s output. What happens instead is that AI frames them. And, over time, that framing can quietly shift from neutral or positive to cautious, qualified, or subtly negative. Although this process does not necessarily affect visibility, it erodes the preference. Instead of recommending your brand as 100% reliable, the model starts talking about it as questionable one. And it’s not a PR issue when a negative mention can become beneficial.
In LLM-driven discovery, negative framing directly affects your conversion. Large language models compress evaluation, comparison, and validation into a single response. If that response repeatedly introduces doubt, caveats, or objections, the decision is often over before the user realizes it.
In this article, you’ll learn what sentiment drift in GEO is, how it forms through reinforcement and echo loops, how to detect it early through language patterns and repeated objections, and how to reverse it using risk-reversal assets, evidence anchors, and third-party verification. If you care about how AI systems decide — not just what they mention — sentiment drift is a metric you can no longer afford to ignore. Visit our Complete GEO Framework to learn more insights on LLM visibility measurement.
In traditional PR, negative mentions are often treated as tolerable and even useful in some cases. A controversial review, a critical article, or a heated forum thread can still drive awareness, spark debate, and ultimately send curious users to investigate for themselves. From this standpoint, visibility and sentiment are loosely coupled, so teams can afford to treat “any press as good press.”
What happens in AI-guided ecommerce is absolutely different. When the model frames a brand as risky, overpriced, unreliable, or not recommended for most users, that framing does not sit in a vague reputational layer. Instead, it directly shapes the outcome of the decision. In practice, negative framing acts like an invisible filter: although your brand may still be mentioned, it is quietly excluded from serious consideration.
Unfortunately, many teams misread the signals the model sends at this point. You may see your brand appear in answers and assume visibility is intact. But appearance without positive or neutral framing is damaging to your LLM visibility because it rarely translates into preference. In fact, negative sentiment often does more damage than absence, because it introduces doubt at the exact moment your potential customers are looking for reassurance.
The negative impact multiplies because LLMs compress evaluation, eliminating the need for users to read multiple reviews, compare sources, and form opinions over time. The model simply synthesizes risk narratives into a single response. If that synthesis leans negative, the buyer rarely clicks through to verify, while the conversation simply moves on to another option. That’s how AI-generated answers in ecommerce work in a nutshell.
From the GEO perspective, the very nature of LLMs reframes sentiment entirely, because you are no longer managing PR in the abstract. Instead, you have to deal with conversion-critical framing inside AI answers. A brand that is consistently described as “fine but risky,” “popular but expensive,” or “good in theory, problematic in practice” loses decisions over time even while maintaining surface-level visibility.
That is why it is essential to control sentiment drift in AI-generated answers and GEO by conducting measurements. The goal is to detect whether LLMs increasingly attach qualifiers, caveats, or warnings to your name. If yes, it means that the system is signaling a real loss in buying power long before traffic or revenue metrics catch up. But what causes the drift?
Sentiment drift in AI-generated answers rarely starts with a broad consensus turning negative. In most cases, it begins small, localized, and easy to miss. The first trigger is usually a single source, such as a critical review, a forum thread, a comparison article, or a policy page that highlights limitations. LLMs like such sources because they offer an alternative point of view on a subject.
On its own, the negative source may not seem harmful. The problem, however, lies in asymmetric visibility multiplied by the avalanche effect. When you cannot prove that the alternative claim is wrong, the model starts relying on it. And, like in a real avalanche, a tiny snowball, a negative claim about your brand, gathers weight, speed, and force with every second, pulling in everything around it until it turns into a disaster.
From the perspective of AI-guided ecommerce, a tiny snowball starts turning into a full-scale avalanche when repeated reinforcement takes over. If the same negative point is echoed even lightly across multiple places, the model begins to treat it as a stable attribute rather than a situational claim. It happens because LLMs are optimized to reduce uncertainty by converging on patterns that appear consistent across sources. Over time, it not only leads to responses that cite the original negative claim but also changes the wording to become more confident: “sometimes reported” turns into “often criticized,” which turns into “known for.”
Once the model starts including a negative framing in its answers, that framing itself becomes a reference point for future generations. Here, you reach the point of no return, the echo loop. At this stage, a small snowball becomes an avalanche: summaries feed summaries, comparisons reuse earlier language, and new answers inherit older conclusions. Sentiment drift no longer depends on a couple of negative sources. Instead, it sustains itself through repetition.
This is exactly why drift feels sudden from the outside. It’s hard to notice a tiny snowball, but an avalanche is hard to ignore. In reality, the system crossed a tipping point where one narrative has changed everything.
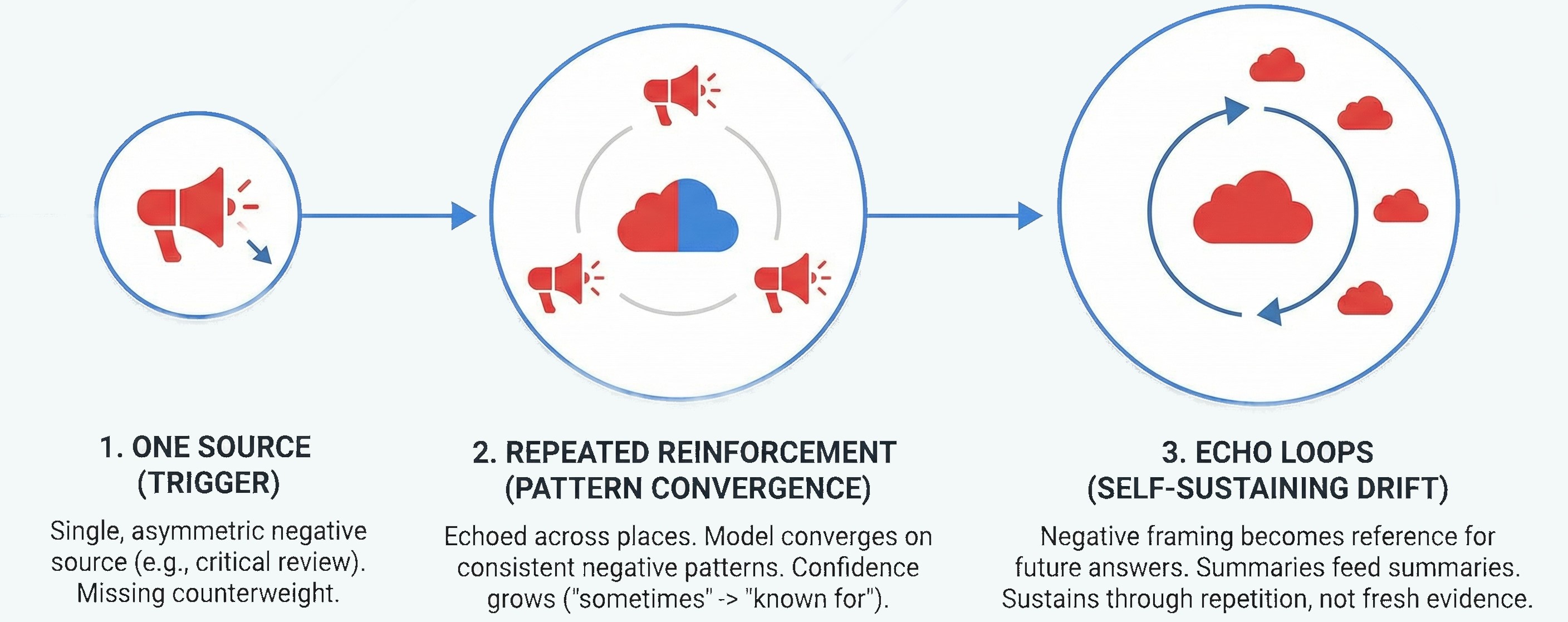
Understanding this mechanism matters because it changes the response strategy. Rather than fighting opinions, you have to interrupt a reinforcement loop. To do this, you need to become a time-traveler who visits the past and reacts to a snowball being thrown.
Detecting sentiment drift in AI-generated answers means learning to read how the model talks about you, looking for specific signals. It will help you find the root cause of the issue — the snowball that has caused or may yet cause the avalanche.
The first signal to pay attention to is trigger-based framing. Drift often appears only after certain follow-up questions: pricing clarification, risk evaluation, alternatives, or “who should avoid this” prompts. If your brand is neutral or positive in broad Explore answers but becomes cautious or dismissive once constraints tighten, it means you are in danger.
Next, watch for recurrent phrases. Since LLMs reuse language when a narrative stabilizes, phrases like “users often report…,” “commonly criticized for…,” “may not be ideal if…,” or “better suited for niche cases” are not random. When the same qualifiers appear across different prompts, stages, or runs, they indicate that the model has internalized a specific framing.
And don’t miss the strongest indicator — repeated objections. These are not generic cons, but the same downside resurfacing across conversations: shipping concerns, pricing ambiguity, reliability doubts, hidden costs, lack of support, unclear availability, etc. When objections recur independently of prompt wording, they stop being edge cases and become default caution flags.
When you try to detect sentiment drift in GEO, it is extremely important to remember that drift detection is about patterns, not severity. If you see one harsh sentence, it does not necessarily equal drift (unless it is not repeated across multiple runs). Consistent soft warnings, however, do. Brands often underestimate this because nothing sounds overtly negative, yet the accumulation of caveats quietly pushes the model toward safer alternatives. Below, we explain what you should do once this has happened.
Once sentiment drift is detected, the goal is to change the evidence environment the model learns from. At this stage, you need to remember that rather than responding to rebuttals or tone adjustments, LLMs respond to credible signals that consistently resolve doubt across sources and contexts. Knowing this feature, you can use three tactics to fix sentiment drift efficiently, addressing the consequences of the avalanche. In simple words, you need to detect the concern that triggers sentiment drift and refute the negative statements. Here is how to do it.
The very first step is to create risk reversal assets. Because drift often forms around uncertainty, clear risk-reversal language directly counteracts that. Refund policies, guarantees, trials, cancellation clarity, and explicit “who this is not for” sections reduce ambiguity. When these assets are explicit, structured, and easy to cite, the model has a safer way to recommend without hedging.
Next come evidence anchors. These are concrete, verifiable artifacts that replace vague claims with proof: comparison tables, transparent pricing breakdowns, quantified outcomes, documented limitations, and summarized reviews that acknowledge trade-offs honestly. While sentiment drift thrives on abstraction, evidence anchors work because they give the model something stable to point to when validating a recommendation.
Finally, third-party verification breaks the echo loop, completely addressing the issues caused by the avalanche. If negative framing originated from a single source that kept getting reinforced, you need independent signals that compete with it. Authoritative reviews, reputable directories, analyst mentions, certifications, and neutral comparisons provide external grounding. Importantly, these sources don’t need to be glowing — they need to be specific, because specificity is what LLMs trust.
And remember that from a GEO perspective, fixing drift is not about suppressing negatives. It’s about making the positive case safer to repeat than the cautionary one. When that happens, sentiment stabilizes, survives follow-ups, and carries through to the decision stage. To learn more about mitigation strategies for sentiment drift, follow this link:
Fixing sentiment drift is never complete without re-testing. It is just optimism disguised as strategy. In GEO, nothing is resolved until the model behaves differently under the same pressure that created the problem.
A proper re-test starts by returning to the exact contexts where drift was detected. You need to try to find the snowball once again, using the same prompt families, follow-up constraints, and Validate and Decide-stage turns where hesitation, caveats, or negative framing appeared before. If you change the test, you lose the signal.
The next important thing is that re-testing must be distribution-based, not anecdotal. As we’ve already mentioned, one answer proves nothing, no matter whether you are looking for the initial negative framing or running a re-test. Instead, you must run multiple variants and repeated turns to see whether the framing shift holds consistently or collapses under slight phrasing changes. Don’t forget that sentiment drift reversal in GEO is only real if the improvement survives variance.
What you measure also matters. Rather than checking for “less negativity,” also look for:
If the model still introduces caution, but now balances it with explicit risk reversal or proof, that’s progress. If the same warning reappears unchanged, the fix didn’t land regardless of how confident the content feels internally. Follow our Conversation-First GEO Measurement Guide to learn about other key components to measure LLM visibility in the era of AI-driven ecommerce.
As you can see, sentiment drift in AI-generated answers is anything but a cosmetic issue. It is one of the fastest ways to lose customers during the Decision stage without ever disappearing. The core shift, however, is simple but critical: negative framing in AI-generated answers is measurable, diagnosable, and reversible. Drift forms through repetition and spreads through echo loops as an avalanche. And it can only be fixed by changing the evidence the model relies on, rather than rewriting copy in isolation.
And when you start tracking drift properly, you stop reacting to individual “bad answers” and start managing patterns, controlling which objections repeat, where hesitation enters the journey, and which stages are most vulnerable.
Most importantly, you don’t guess whether your fixes worked. Instead, you re-test, verify, and prove the reversal under the same conditions that created the problem. If you want a structured way to respond to negative framing in GEO, you’ve come to the right place. Contact us now to learn more about our product and how it can help monitor drift and suggest fixes.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.
