
Genixly team
-
November 26, 2025
Artificial Intelligence and Business Analytics: The Emerging Trends That Reshape the Enterprise Approach to Data
Lear more
EU AI compliance guide to building AI apps under EU AI Act and GDPR. Learn workload classification, data residency, audit logs, model routing, and architecture.

EU AI compliance is now a practical requirement for any team building AI apps in Europe. Between the EU AI Act and GDPR, compliance no longer means adding a privacy policy, updating legal pages, or collecting consent at the end of development. It shapes the product architecture itself — where inference happens, how personal data moves, which systems need audit logs, when human oversight is required, whether a model call can cross EU borders, and so on.
Many organizations, however, still start in the wrong place. They pick a model, build a prototype, choose a vendor, or connect an API before they understand the legal and technical boundaries. Then, late in the process, they discover that their data flows, logging design, human review process, or deployment model does not support EU AI Act compliance or GDPR for AI. At that point, compliance becomes expensive rework instead of a normal part of engineering.
The real challenge of building AI apps in the EU is structural: AI regulation in Europe directly affects infrastructure choices, workload classification, model routing, data residency, risk management, and evidence collection. A compliant AI app needs these decisions built in from day one, not patched on after the demo works.
Therefore, in this guide, we explain how to build AI systems that are useful, production-ready, and aligned with the EU AI Act and GDPR. You’ll learn how to classify workloads, choose the right deployment posture, design audit logs, control cross-border AI calls, and build AI compliance architecture that can survive real users, real audits, and real business requirements.
Who this guide is for: CTOs, founders, AI agencies, product teams, and technical leaders building AI apps for European customers, especially when GDPR, the EU AI Act, data residency, audit logs, or high-risk AI obligations matter.
What you’ll learn:
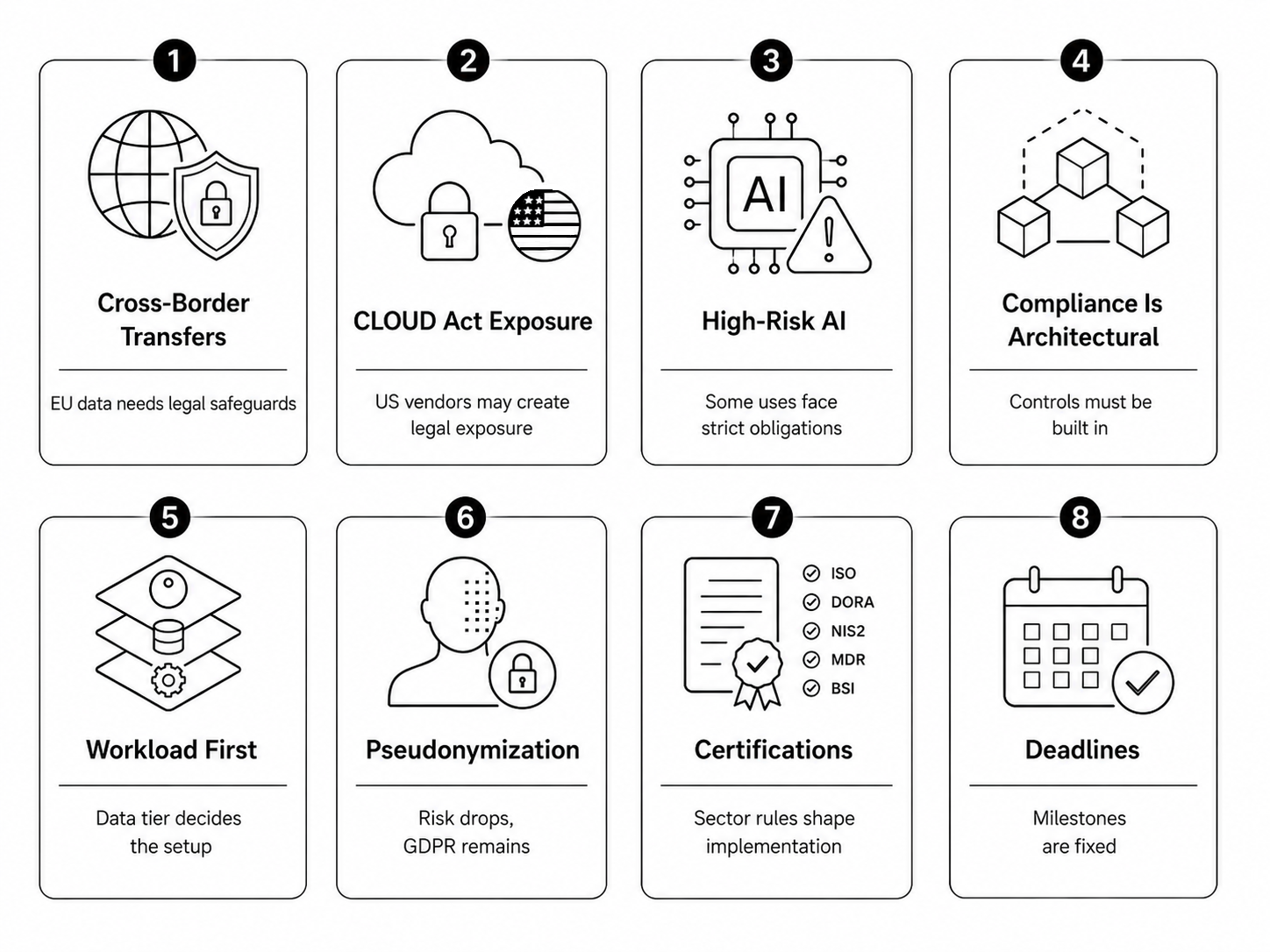
Before discussing architecture, tools, or implementation, you need to understand one thing: most constraints around EU AI compliance are legal and structural. If you ignore them early, they will surface later as blockers, rework, or audit failures. Below, we describe the core 8 limitations that define how AI systems must be built in Europe:
Since you cannot cross these boundaries, consider them the foundation you build on. The rest of this guide will show how to turn them into a working, production-ready architecture rather than treating them as blockers.
A year ago, you still had to choose between capability and compliance, but that’s no longer the case. Today, you can build serious AI systems that meet EU AI compliance requirements, but only if you understand what has actually changed and how to navigate it.
A few things have shifted recently in the market that most teams haven’t fully caught up to yet. First, EU-hosted models are finally good enough. Today, models like Mistral, running on providers such as Hetzner, can handle the majority of real business tasks — extraction, classification, routing, summarization, etc. For 70–80% of workloads, they are enough because you don’t need frontier models here. And at scale, running them yourself can be significantly cheaper than relying on APIs.
Second, frontier models are available within EU boundaries. Through Amazon Web Services Bedrock in Frankfurt, you can access models like Claude with EU data residency guarantees. The setup isn’t perfect from a legal standpoint, but it’s a practical option many teams overlook, especially when they assume “Claude = US only.”
Put together, this means one thing: you no longer need to compromise on capability to make your AI app compliant with the European legislation. However, you do need to design for compliance from day one.
From the standpoint of everything we’ve noted above, every architectural decision comes down to a single question: Where does inference happen? From that, we highlight three clear patterns that we call Postures:
| Posture | Inference | CLOUD Act exposure |
|---|---|---|
| A — Sovereign Maximum | Mistral on Hetzner (vLLM) | None — no US-owned company in the path |
| B — Pragmatic Frontier | Claude on Bedrock Frankfurt (EU inference profile) | Theoretical (AWS is US-owned). Mitigated by EU residency + DPA. Acceptable for most. |
| C — Hybrid | Mistral default; Claude on Bedrock for hard reasoning | Mixed by workload classification |
Let’s explain them in more detail. From the perspective of the EU AI compliance, Sovereign Maximum provides full control without ambiguity. It means that everything runs in the EU, without US providers in the loop. This is the only acceptable option for highly regulated environments, such as healthcare, public sector, defence, certain financial use cases, etc.
As for the Pragmatic Frontier Posture, it offers enterprise-grade capability within EU boundaries. You use frontier models via EU endpoints (like Bedrock Frankfurt). While your data stays in the EU, the provider is still US-based. For most SaaS and mid-market use cases with US and EU customers, this is an acceptable trade-off.
And, of course, there is the Hybrid pattern. With this Posture, routine workloads run on EU-hosted models, but hard problems get routed to frontier models when needed. This is where most production systems land once you move past theory and start dealing with real constraints.
And instead of trying to pick “the best” option, you need to figure out which Posture fits your data and your risk profile.

Before you build anything, run your use case through this simple EU AI compliance filter:
In practice, however, most systems end up hybrid, while some go fully sovereign. Very few stay purely “frontier-first” once AI compliance enters the picture.
Now, if you understand this section, you already have a working decision framework. Everything else below is just its implementation.
Now, let’s say a few more words about the regulatory reality behind every AI project in Europe. If you are serious about EU AI compliance, you cannot treat regulation as something you handle later. In practice, that approach almost always backfires, because laws like the General Data Protection Regulation and the EU AI Act define what you’re allowed to build and how you have to build it.
Therefore, compliance is a part of the architecture rather than just a layer.
Once you accept that, things actually get simpler. Instead of guessing what might break later, you start with the constraints and design with them in mind so that a lot of the compliance work, such as logging, documentation, or risk controls, naturally falls out of the system.
The General Data Protection Regulation has been in force since 2018, and most teams are familiar with its visible parts — consent, data access requests, breach notifications. What often gets overlooked is how deeply it affects system design.
Several articles are especially important for anyone building AI systems compliant with EU legislation. GDPR Article 28, for instance, requires processors to provide sufficient guarantees for compliant data handling. GDPR Article 32 mandates appropriate technical and organizational measures. And most critically, GDPR Articles 44–49 govern how and when personal data can leave the EU.
In practice, these transfer rules are what shape architecture decisions. If personal data moves outside the EU, you need a legal basis — such as an adequacy decision (like the EU–US Data Privacy Framework), Standard Contractual Clauses, or additional safeguards. The situation remains uncertain, especially after the Schrems II ruling invalidated the previous Privacy Shield framework, and with further legal challenges expected.
This is why many teams default to a “sovereign-first” approach — not for ideological reasons, but to avoid relying on unstable legal mechanisms.
On top of GDPR, the EU AI Act introduces a second layer of requirements, focused specifically on AI systems.
The regulation entered into force in 2024 and is being applied in stages. Prohibited use cases, such as social scoring or certain forms of biometric surveillance, have already been banned since February 2025. The more demanding requirements apply to high-risk systems and general-purpose AI models, with full enforcement starting on August 2, 2026.
High-risk systems are defined in Annex III of the AI Act, and the scope is broader than many expect. It includes AI used in hiring, credit scoring, insurance underwriting, education, access to essential services, and more. If your application falls into one of these categories, you are required to implement a set of controls that go far beyond standard software practices:
These requirements are often treated as documentation tasks added after development. In reality, you should treat them as architectural decisions because if you design your system with audit logs, access controls, and structured workflows from the start, much of the required documentation is generated naturally. If you don’t, compliance becomes a separate and expensive project.
And it’s not the only reason to treat EU AI compliance as a part of the architecture rather than just a layer you add on top, because there is the enforcement reality. Penalties under the AI Act are significant — up to €35 million or 7% of global turnover for prohibited practices, and up to €15 million or 3% for non-compliance with high-risk obligations.
From this perspective, you won’t ask whether EU AI compliance matters or not. And there is certainly no doubt that building the right architecture from scratch is cheaper than fixing it later.
The CLOUD Act is one of those topics that shows up in every serious EU AI discussion. At a high level, the rule is simple: US authorities can require US-based companies to provide access to data, even if that data is stored outside the United States. That includes data hosted in EU regions by providers like Amazon Web Services, Google, or Microsoft.
This creates an uncomfortable reality. Even if your infrastructure is physically located in Europe, the legal jurisdiction of the provider still matters. That said, the situation is more nuanced than most headlines suggest. These are the 3 main aspects you should keep in mind when it comes to the CLOUD Act problem and the EU AI compliance:
First, the theoretical risk is real — but rarely exercised. There are very few public cases where EU customer data was actually accessed under the CLOUD Act. For large enterprises or public institutions, this risk is taken seriously. For a mid-sized SaaS company, the practical likelihood is low — but not zero.
Second, Europe is actively building alternatives. The EU is investing heavily in sovereign cloud initiatives and regulatory frameworks that reduce reliance on non-EU providers. New programs and procurement requirements are already pushing regulated industries toward EU-controlled infrastructure. In practice, this means that “sovereignty” is becoming less of a preference and more of a requirement in certain sectors.
Third — and most importantly — this is not a binary decision. The CLOUD Act is often framed as “safe vs unsafe infrastructure.” That’s the wrong way to think about it. In reality, it’s a workload classification problem that looks as follows:
This workload classification explains why most real systems end up with a hybrid architecture (Posture C): EU-hosted by default, with controlled use of external services where justified. But let’s say a few more words about the importance of the workflow classification from the perspective of the EU AI compliance.
Before you choose a cloud provider, model, database, vector store, or orchestration layer, you figure out what kind of workload you are actually building. You never start with architecture, even if it may look obvious to do so, because the first decision is data classification.
A chatbot that answers questions from public marketing pages does not need the same architecture as an HR assistant that processes employee records. A document extraction workflow for invoices does not carry the same risk as an AI system used for medical triage or credit scoring. What happens when you treat all workloads the same? There are two possible outcomes: you either over-engineer simple systems or under-protect sensitive ones.
So the correct sequence is simple: Classify the workload first and only then choose the architecture.
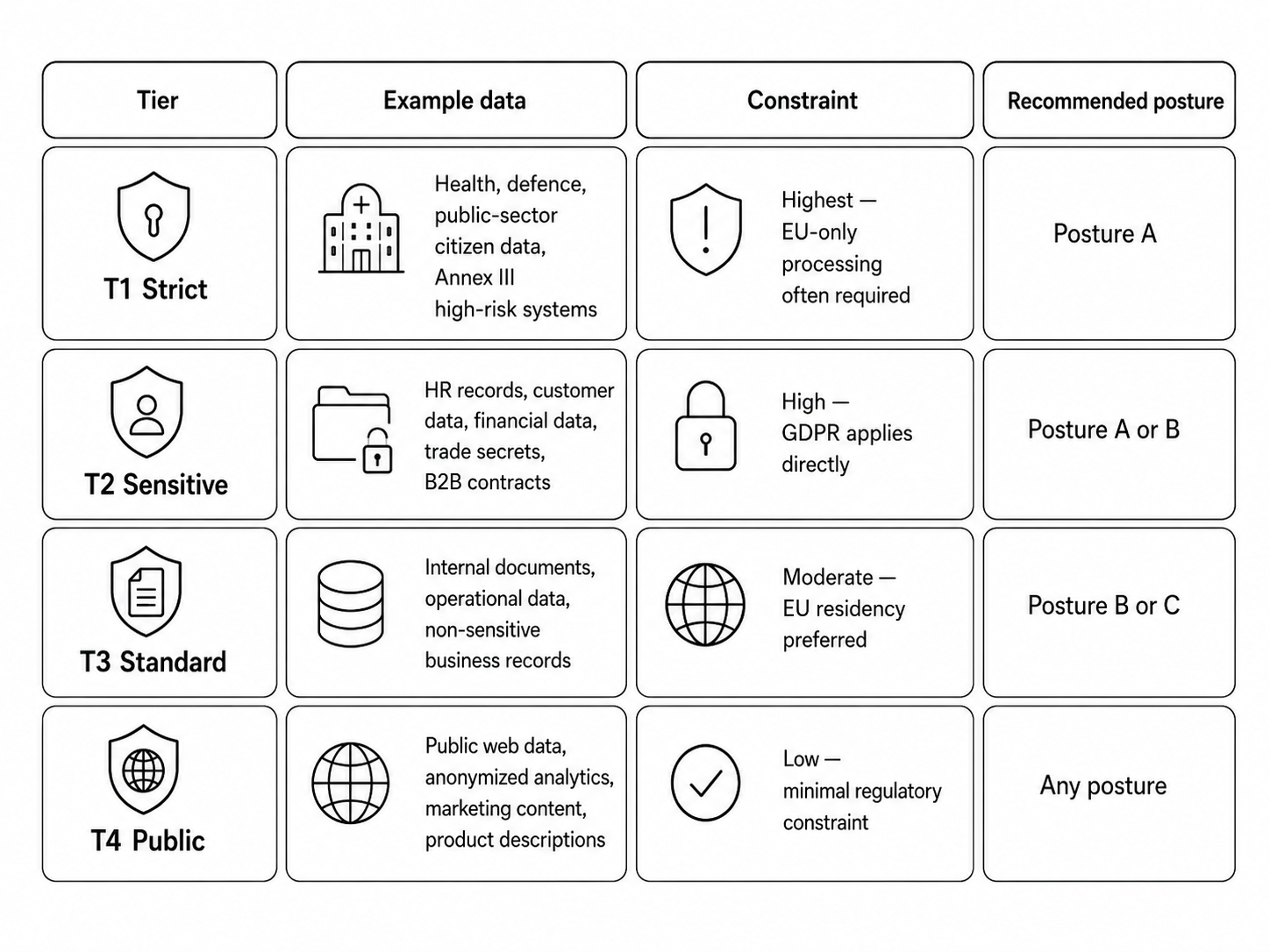
Here is a practical four-tier framework for AI apps built with the EU legislation compliance in mind:
| Tier | Data | Constraint | Posture |
|---|---|---|---|
| T1 Strict | Health data under GDPR Article 9, defence data, public-sector citizen data, Annex III high-risk systems involving EU citizens | Sectoral law or customer requirements mandate EU-only processing. CLOUD Act exposure is unacceptable. | Posture A only. |
| T2 Sensitive | Personal data at scale, HR records, customer databases, financial data, trade secrets, B2B contracts | GDPR applies directly. EU residency is strongly preferred or required. CLOUD Act exposure must be documented in the DPIA and accepted explicitly. | Posture A or Posture B with explicit acceptance. |
| T3 Standard | Internal documents, operational data, non-sensitive business records, public-facing content with limited personal data | Standard GDPR data minimization applies. EU residency is preferred, but not always mandatory. | Posture B is usually fine. Posture C if mixed with T2 data. |
| T4 Public | Public web data, anonymized analytics, marketing content, product descriptions, public documentation | Minimal regulatory constraint. Speed, cost, and capability matter more than sovereignty. | Any posture. Posture B usually wins on capability. |
This table looks simple, but it changes the whole architecture conversation.
T1 Strict workloads leave almost no room for interpretation. If you are processing health data, public-sector citizen data, defence-related information, or high-risk AI decisions involving EU citizens, you should assume a sovereign setup from the beginning. That means EU-controlled infrastructure, EU-hosted inference, strict audit logs, and no unnecessary exposure to US-owned providers. This is not the place for “maybe the contract is enough.” The risk profile is too high.
T2 Sensitive workloads are where most serious business AI systems land. HR automation, customer support with personal data, contract analysis, financial workflows, and CRM intelligence often fall into this tier. You may be able to use a provider like Bedrock Frankfurt or another EU-region service, but only after documenting the risk. This is where the DPIA matters. The question is not “is this allowed?” but “can we explain and defend this architecture if a customer, auditor, or DPO asks?”
T3 Standard workloads are more flexible. Internal knowledge assistants, operational reporting, product content workflows, and routine document automation may not require the strictest deployment model. Here, EU data residency is still a good default, but you can make more pragmatic choices, still following EU AI compliance requirements. If the workload later starts touching sensitive data, move it into T2 and adjust the architecture.
T4 Public workloads are the least constrained. If the data is already public or genuinely anonymized, capability and speed can take priority. This is where frontier models often make sense because the compliance risk is much lower. But “public” should not become a lazy label. Internal pricing data, customer notes, employee names, or private contracts are not public just because they appear in a document pipeline.
The main value of this framework is that it prevents vague compliance debates. Once the tier is clear, the deployment posture becomes much easier to choose. However, this step forces an uncomfortable but necessary conversation because you figure out what data really flows through the system, who can access it, where it goes, and what happens when something fails.
That conversation is the foundation of your architecture that can keep up with EU AI compliance. Skipping it is how AI projects become expensive compliance problems later.
People in Europe love asking about certifications. Procurement teams need them. Security specialists never ignore them. Enterprise customers treat them as a shortcut for trust. But here is the practical truth: not every certification matters equally when it comes to EU AI compliance. Therefore, your goal is not to collect every badge available. What you really need is to know which certifications actually affect your architecture, sales process, and deployment timeline. Let’s figure that out.
ISO 27001 is the standard most enterprise buyers expect first. It covers information security management: access control, incident response, vendor management, business continuity, risk management, and internal security processes.
It is important to understand what ISO 27001 is — and what it is not.
It is not a certification for your AI model or your product. It does not prove that your AI app is compliant with the EU AI Act. Instead, it proves that your company has a structured information security management system.
For early-stage startups, ISO 27001 may be too heavy too soon. But if you sell to enterprise customers in Europe, especially in regulated sectors, you will eventually need it. Without it, security reviews become harder, sales cycles get longer, and some procurement processes simply stop.
ISO 27001 should usually be your first certification target once enterprise sales become serious.
ISO 27701 extends ISO 27001 into privacy information management. If ISO 27001 covers general security questions, ISO 27701 focuses on managing personal data.
That makes it highly relevant for AI systems that process user records, employee data, customer communication, documents, or any form of personal data at scale.
It does not replace GDPR compliance. But it shows that your privacy processes are structured, documented, and auditable. For buyers who care deeply about privacy — especially DPOs, legal teams, healthcare companies, financial institutions, and public-sector customers — this can be a meaningful trust signal.
Get ISO 27701 after ISO 27001 if privacy is central to your product or customer base.
ISO 42001 is the first certifiable management system standard focused specifically on AI. It covers how organizations develop, deploy, monitor, and govern AI systems.
Today, many buyers still do not ask for it. That will likely change as the EU AI Act becomes more relevant in procurement conversations. Once customers begin asking how you manage AI risk, model monitoring, human oversight, and responsible deployment, ISO 42001 becomes easier to justify.
Again, this is not a magic compliance certificate. It will not automatically make your AI app legal under the EU AI Act. But it can help prove that your company has a serious AI governance process.
ISO 42001 is not usually the first certification to pursue. It makes sense after ISO 27001 and, in many cases, ISO 27701.
BSI C5 is the Cloud Computing Compliance Criteria Catalogue from Germany’s Federal Office for Information Security. It matters most when your infrastructure choice needs to satisfy German enterprise or public-sector expectations.
For AI apps, BSI C5 is usually not something you obtain yourself unless you are a cloud provider. Instead, you rely on the infrastructure provider’s attestation. If your stack runs on cloud infrastructure, your customer may ask whether that provider meets BSI C5 requirements.
This matters especially in Germany, where procurement teams often care not only about where data is hosted, but also whether the provider can prove mature cloud security practices.
Do not try to get BSI C5 for your own AI app unless you operate cloud infrastructure. Choose providers that already have relevant attestations.
BSI TR-03161 is a technical guideline for digital health applications in Germany. If you are building a DiGA — a reimbursable digital health app — this becomes highly relevant.
Unlike ISO 27001, which certifies your management system, BSI TR-03161 goes much closer to the product. It covers concrete technical requirements such as authentication, encryption, session management, audit logging, and source code review readiness.
This is where many teams underestimate the effort. Digital health is not just “an app with sensitive data.” It is a regulated product category with strict technical and procedural expectations. Certification can take months and may affect product decisions, supported devices, security architecture, and development workflow.
If your AI system touches DiGA territory, plan for BSI TR-03161 early. It is not something you add two weeks before launch.
BSI TR-03185 focuses more on the software development process. It is especially relevant for manufacturers of digital health applications and complements the more product-level requirements of TR-03161.
This matters because health-related AI products are judged not only by what the final software does, but also by how it is built, tested, reviewed, and maintained. Secure development practices become part of the evidence.
Even if this requirement does not apply to your product immediately, it is worth tracking if you plan to operate in German digital health.
Treat TR-03185 as part of the long-term DiGA and medical software roadmap, especially if health becomes a core vertical.
The DiGA pathway is not simply a technical certification. It is the route into Germany’s reimbursable digital health app market through the BfArM directory.
To get there, a product typically needs much more than secure hosting. You may need CE marking under the Medical Device Regulation, ISO 27001, BSI TR-03161, GDPR evidence, clinical evidence of positive healthcare effects, and interoperability requirements such as FHIR.
That means DiGA is both a compliance path and a business model decision. Once listed, the app can be reimbursed through statutory health insurance. But getting there requires planning, budget, clinical evidence, and a product that can survive a detailed review.
Once listed, statutory health insurance reimburses the app for prescribed patients. Median launch price is €514 per three-month prescription, settling at €221 after the first-year price negotiation.
It is the most structured digital health reimbursement pathway in Europe and the entry point for any non-EU DTx wanting Germany's 73 million insured lives.
The Medical Device Regulation applies when software diagnoses, monitors, predicts, treats, or supports decisions related to disease, injury, or health conditions.
This is one of the most important lines to watch in AI development. A wellness chatbot and a symptom assessment tool may look similar to users, but they can fall into very different regulatory categories. If your AI system influences medical decisions, you may be building medical device software.
That changes everything: classification, conformity assessment, documentation, risk management, clinical evaluation, post-market monitoring, and timelines.
If your AI app has any health-related decision-making function, assess MDR relevance before building the product logic.
DORA, the Digital Operational Resilience Act, matters if you build AI systems for banks, insurers, asset managers, payment institutions, or other financial organizations in the EU.
Its focus is not AI specifically. Its focus is operational resilience: ICT risk management, third-party provider oversight, incident reporting, resilience testing, and exit strategies.
From the EU AI compliance standpoint, that means vendor choices matter. If your AI workflow depends on an external model provider, cloud platform, or workflow engine, your customer may need to document that dependency, assess the risk, and prove they can recover if the provider fails.
In finance, compliance is not only about model behavior. It is also about resilience, vendor risk, incident response, and continuity.
NIS2 expands cybersecurity obligations across many important sectors, including digital infrastructure, public administration, manufacturing, food, postal services, and others.
Even if you are not directly regulated, your customers may be. That means your AI app can inherit requirements through procurement and supply-chain reviews.
This is especially important for agencies and SaaS companies. A customer under NIS2 may ask about your security controls, incident handling, access management, logging, vendor dependencies, and continuity planning. You may not be the regulated entity, but you still become part of the risk surface.
If you sell AI systems into critical or important sectors, expect NIS2-style security questions even when the law does not apply to you directly.
TISAX is the information security assessment standard used across the automotive industry, especially in Germany.
If you want to work with OEMs or major suppliers, TISAX may become a practical requirement before serious conversations begin. This is particularly relevant for AI systems that process supplier data, production data, engineering documentation, quality data, or connected vehicle information.
If automotive is a target vertical, plan for TISAX early. Without it, many doors stay closed.
SOC 2 is common in the US and often appears in procurement checklists, especially when customers operate internationally.
It can be useful if you sell to US companies or global enterprises. However, in a pure EU context, SOC 2 is usually less important than ISO 27001. Many European buyers understand ISO standards better and treat them as more relevant for security management.
But that does not make SOC 2 useless. It just means it should not be your first move if your primary market is Europe.
SOC 2 is a good complement for transatlantic sales. For EU-first positioning, lead with ISO 27001.
The good news is that you do not need every certification at once to make your application compliant with EU norms and requirements. In fact, trying to pursue every certification too early can drain the budget and slow the product down. So, here is a more practical certification roadmap for AI companies and products in Europe:
| Stage | What to Prioritize | Why It Matters |
|---|---|---|
| First Serious Enterprise Sales | ISO 27001 | Establishes baseline trust for information security. |
| Privacy-Sensitive Customers | ISO 27701 | Strengthens GDPR-facing privacy governance. |
| AI Governance Maturity | ISO 42001 | Shows structured management of AI-specific risk. |
| Health Vertical | BSI TR-03161, TR-03185, MDR, DiGA requirements | Required or expected for regulated digital health products. |
| Finance Vertical | DORA readiness | Required for operational resilience and vendor-risk discussions. |
| Automotive Vertical | TISAX | Often necessary to work with German OEMs and tier-1 suppliers. |
| German Public Sector / Regulated Cloud Buyers | Infrastructure with BSI C5 attestation | Helps satisfy cloud-security expectations without certifying your own app as a cloud provider. |
| US or Global Enterprise Sales | SOC 2 | Useful when selling into US-heavy procurement environments. |
The main point is simple: certifications are not decorations. They are market-access tools that you should choose based on who you sell to, what data you process, and which sector you operate in. For most EU AI companies, the smart path is ISO 27001 first, then ISO 27701, then ISO 42001, with sector-specific requirements added only when the vertical justifies the cost.
Once you understand the regulatory limits, the next step is pure engineering. This is where EU AI compliance stops being a legal conversation. At this stage, you need an architecture that keeps data under control, routes each workload to the right inference layer, logs every important action, respects permissions, and still lets the product move fast.
The good news is that there is a core pattern that does not change much from project to project. Whether you choose a fully sovereign setup, a pragmatic Bedrock-based deployment, or a hybrid model, the same four layers keep appearing: data, orchestration, intelligence, and governance. The main point of the four-layer model is a stable blueprint you get before arguing about tools. So, here are the basics of this blueprint:
| Layer | Purpose | Default Tools for EU Deployments |
|---|---|---|
| Data | Stores the sources of truth, retrieval indexes, files, structured records, and business data the AI system depends on. | Postgres, pgvector, Qdrant, MinIO, Hetzner Object Storage |
| Orchestration | Moves work between systems and coordinates business workflows: triggers, approvals, retries, queues, and writebacks. | n8n, Dagster for batch jobs, FastAPI, Postgres triggers |
| Intelligence | Handles models, retrieval, prompting, embeddings, structured outputs, and inference routing. | Mistral via vLLM, Claude via Bedrock Frankfurt, BGE-M3 embeddings |
| Governance | Controls identity, permissions, audit logs, monitoring, approvals, and operational visibility. | Keycloak, Langfuse, Grafana + Prometheus, append-only Postgres audit logs |
This structure is especially important because AI apps fail when these layers are blurred. While a prototype can survive with one script calling one model, a production system cannot. Once real customer data enters the picture, you need clear boundaries: where data is stored, where logic runs, where model calls happen, who can access what, and how every important action is recorded.
From the perspective of EU AI compliance, it also has a significant role because architecture and evidence are closely connected here. If your system cannot show what happened, who triggered it, which model handled it, what data was used, and which permission checks applied, your compliance story becomes guesswork that never survives audits. Let’s dive deep into the details.

This is one of the most important rules in the whole EU-compliant AI architecture: workflow tools should not call models directly.
For example, n8n should not call vLLM, Claude, or any other model endpoint on its own. Instead, n8n should call a controlled FastAPI layer, and FastAPI should call the model.
At first, this may feel like unnecessary complexity. In practice, it prevents a long list of future problems.
FastAPI becomes the single place where you manage prompt construction, output validation, structured response schemas, rate limits, model routing, fallback logic, tracing, and PII filtering. Without this layer, every workflow starts re-implementing the same logic in a slightly different way. That creates inconsistency, security gaps, and painful maintenance.
The clean pattern is simple:
Workflow triggers the task. FastAPI prepares and controls the model call. The model returns a structured response. The workflow continues.
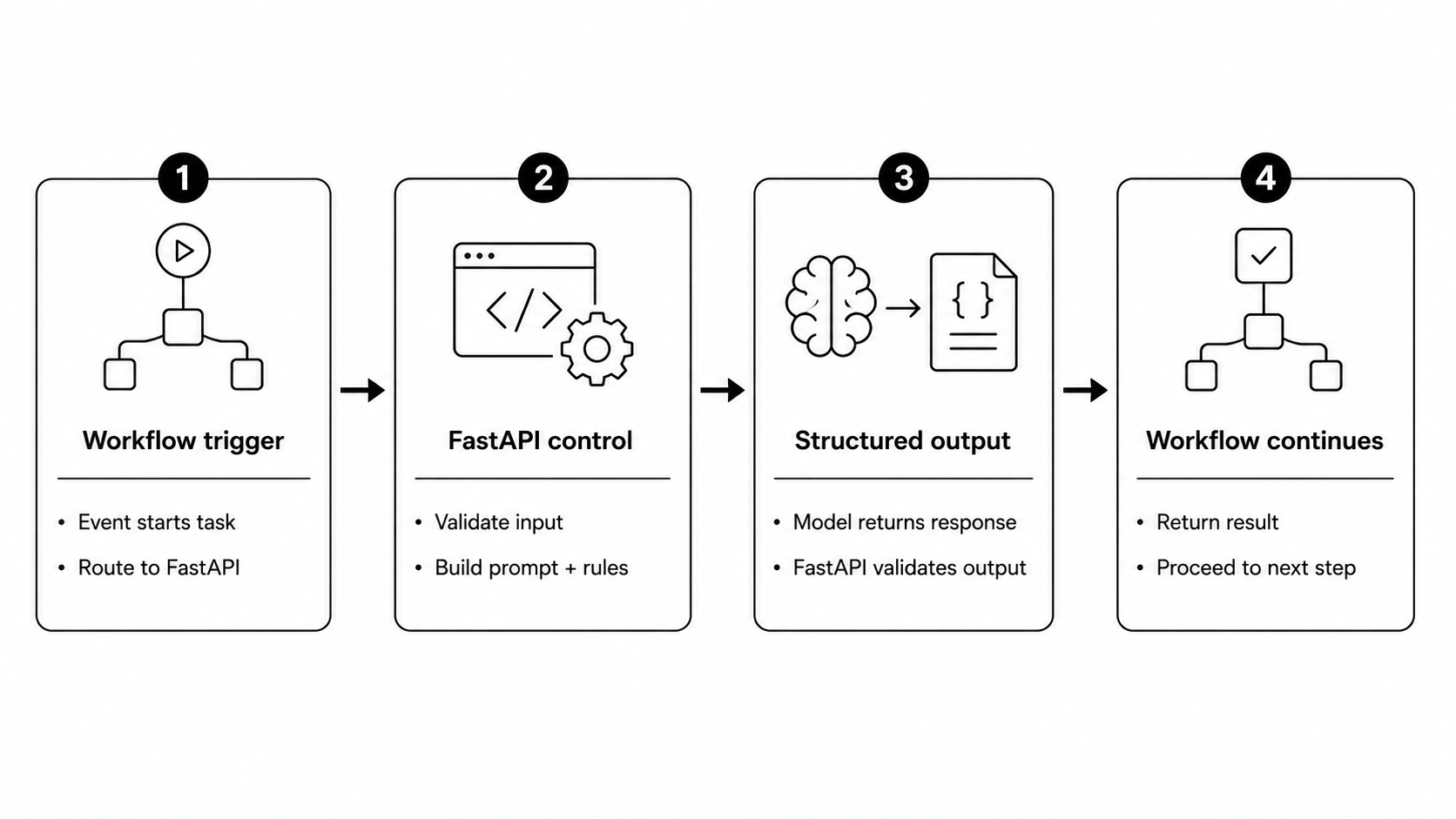
That separation keeps the system understandable.
Audit logging is not the same as application logging. Let’s explain this statement.
n8n logs are useful for debugging workflows. Application logs are useful for diagnosing technical failures. But neither should be your primary compliance record.
For high-risk AI systems, the audit trail needs to be deliberate: append-only, timestamped, preserved according to a retention policy, and difficult to alter. That is why the audit log belongs in Postgres, in a dedicated table designed for this purpose.
This matters for the EU AI Act compliance because automatic event logging is not a “nice to have” for high-risk systems. It is part of the expected evidence base. The system should be able to reconstruct what happened without relying on scattered logs across different tools.
A useful audit record should answer questions like:
If you build this from day one, documentation becomes much easier later.
Permission control cannot stop at the frontend. In a compliant AI system, user identity should travel through the full stack: from the frontend login, through Keycloak, into orchestration, into retrieval, and into the database or vector store. Each layer needs to know what the user is allowed to see or do.
This is especially important for RAG systems and internal assistants. Without permission-aware retrieval, a model can accidentally surface documents that the user should never access. And rather than being a model problem, it is an architecture problem.
So, a cleaner pattern looks like this:
Keycloak manages identity. Postgres enforces Row Level Security. Qdrant filters retrieval using metadata. FastAPI passes the user context into every request.
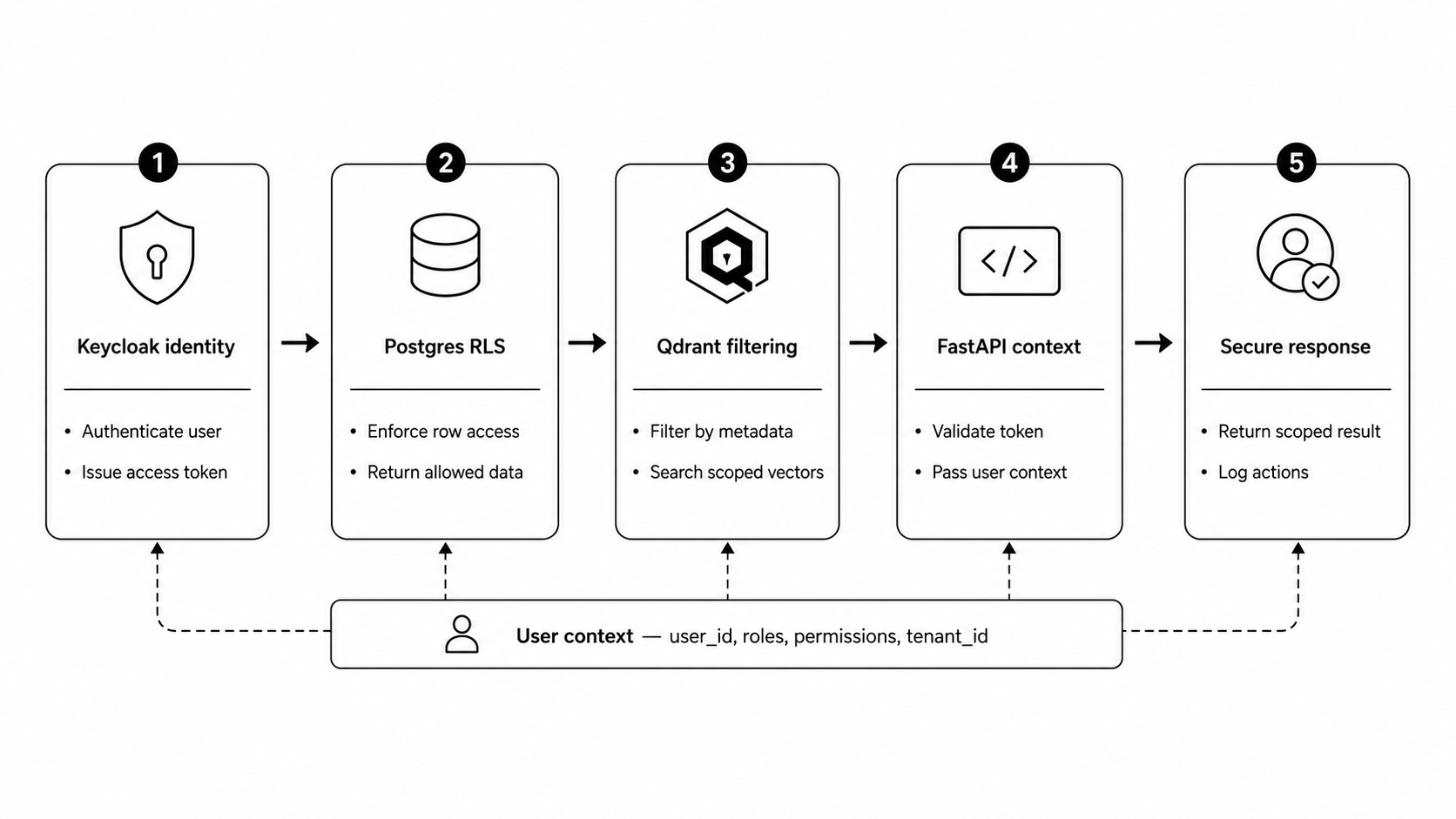
The model should never be asked to “decide” whether the user is allowed to see something. That decision should happen before the context reaches the model.
Many AI prototypes start to fail gradually, so, at first, you don’t even notice that costs and latency rise a little, while model outputs slightly degrade. Nobody notices anything bad until the project stops working as intended. That is precisely why observability belongs in the core architecture, not in a later cleanup phase.
For instance, Langfuse should trace LLM calls: prompts, outputs, token usage, cost, latency, model version, and errors. Grafana and Prometheus should track infrastructure health: CPU, memory, GPU usage, queue depth, request latency, failure rates, and uptime. Below is a more detailed plan that can help you use the correct instruments to answer practical questions:
The best approach to observability is to stop treating it as technical hygiene and start considering it the only way to keep an AI app reliable after launch.
So, this four-layer model is not about using a fashionable stack or creating unnecessary complexity. Everything is in its place here, giving every responsibility a clear home:
When these layers are clean, the system becomes easier to build, explain, audit, and extend, moving one step closer to EU AI compliance.
While the four-layer model gives you the structure, the deployment Posture decides where each layer runs. From this perspective, the data, orchestration, and governance layers stay mostly consistent. What changes are where inference happens, which provider handles the model call, and how much legal exposure the architecture can tolerate. Let’s see what changes from Posture to Posture.
This is the architecture you choose when CLOUD Act exposure is not acceptable for EU AI compliance.
In this posture, the entire system runs on EU-controlled infrastructure. The model runs on Hetzner. The data stays in Europe. The embeddings stay in Europe. The vector store, object storage, workflow engine, audit logs, and identity layer all stay under the same sovereign boundary.
This is the strongest option for the public sector, healthcare, defence, regulated finance, and any workload where using a US-owned provider would create unacceptable legal or procurement risk.
For the EU-compliant application stack, Hetzner cloud instances are usually enough. CCX instances work well for CPU-heavy services, while AX dedicated servers make sense for sustained workloads.
For Mistral inference, you need GPU capacity. Hetzner offers both GPU cloud and GPU dedicated options. The typical sizing looks like this:
| Model | Typical Setup | Approximate Monthly Cost |
|---|---|---|
| Mistral 7B Instruct | Single L40S or A100 80GB | €600–1,200/month all-in |
| Mixtral 8x7B | A100 80GB | €1,000–2,000/month |
| Mistral Large 2 | Multiple GPUs or rented cloud GPU capacity | €3,000–6,000/month |
At production volume, this can be much cheaper than calling external AI APIs. The original estimate is roughly 5–10× cheaper than the equivalent OpenAI API spend once usage is high enough.
The break-even point is usually around 2–5 million tokens per day. Below that, an API-based setup like Bedrock is often cheaper because you avoid fixed GPU cost. Above that, self-hosting starts to win.
Use vLLM for production.
Do not use Ollama as the production inference server. Ollama is useful for local testing and prototypes, but it is not designed for high-concurrency production traffic in the same way.
vLLM is built for serving models efficiently. Its main advantage is PagedAttention, which helps manage the KV cache across many concurrent requests.
Here is the simple version. When a model generates text, it stores attention information from previous tokens in memory. That memory is called the KV cache. As conversations get longer and more users send requests simultaneously, the cache grows quickly. If it is managed poorly, GPU memory becomes the bottleneck.
PagedAttention breaks this cache into smaller pages and reuses memory more efficiently, especially when requests share common prefixes such as system prompts or standard instructions. In production, that can mean 2–10× better throughput under load. So, your app becomes not only EU-AI-compliant but also efficient.
On a single A100 80GB, vLLM can typically serve 50–100 concurrent users for a 7B-class model.
The default workhorse is Mistral 7B Instruct.
It is fast, practical, multilingual, and good enough for many business tasks: extraction, classification, routing, summarization, and structured generation. It supports a 32K context window, handles German, English, and several other languages, and can fit into roughly 6GB VRAM when quantized.
For harder workloads, use Mixtral 8x7B. It gives you stronger reasoning and better handling of more complex tasks while staying practical to host.
For cases where Mixtral is not enough, use Mistral Large 2. It has a 128K context window, supports 80+ languages, and offers stronger reasoning capability. The only downside here is that this model also requires a heavier GPU setup.
The model lineup should not be treated as fixed. Newer options worth tracking include:
The model landscape changes quickly, so update the lineup quarterly.
For embeddings, use BGE-M3 from BAAI.
It is open-weight, multilingual, and supports dense, sparse, and multi-vector retrieval. In this Posture, the important point is not only performance — it is data boundary control, which is crucial for your EU AI compliance.
Run embeddings on the same Hetzner infrastructure as the inference server. Do not call an external embedding API.
This matters for compliance because embeddings still process document content. If you send documents to OpenAI’s embedding API, you have already sent that content outside the sovereign boundary. That defeats the purpose of choosing Posture A in the first place.
Use Qdrant, self-hosted on Hetzner.
It is a strong default for production vector search, especially when you need permission-aware retrieval for your EU AI compliance. Qdrant supports payload filtering, which lets you filter retrieved documents by metadata such as tenant, department, role, or access level.
That is essential for internal assistants and RAG systems, where users must only retrieve documents they are allowed to see.
Use Qdrant when you need:
There is also a simpler alternative: pgvector inside Postgres.
For smaller datasets, pgvector is often enough and saves you from running a separate vector database. The decision rule is straightforward:
| Dataset Size | Recommended Option |
|---|---|
| Under 1 million vectors | pgvector is usually enough |
| 1–10 million vectors | pgvector can still work, depending on latency and recall needs |
| Above 10 million vectors | Qdrant usually wins |
The original recommendation is to avoid ChromaDB, Weaviate, and Pinecone in this architecture:
Use Docling from IBM.
It is open source and handles PDFs, Office documents, and images. The key advantage is structure preservation. For AI workflows, this matters because the model does not just need text — it needs text with enough layout and structure to understand what it is looking at.
Compared with Unstructured.io, Docling is the preferred choice in this architecture for how LLMs actually consume documents.
The practical recommendation is simple: replace Unstructured with Docling in 2026.
For object storage, use Hetzner Object Storage or self-hosted MinIO.
Both options give you S3-compatible storage. Use encryption at rest, isolate buckets per customer, and configure lifecycle policies for retention compliance.
This is where raw documents, parsed files, exports, generated reports, and other file-based assets can live without crossing the infrastructure boundary, which is important from the perspective of EU AI compliance.
For this architecture, the default deployment method is Docker Compose.
Not Kubernetes.
A full stack can run on one or two Hetzner servers:
Kubernetes only becomes necessary when you cross multi-server scale or need specific scheduling features. For most 50–500-person Mittelstand customers, Docker Compose is simpler, faster, and easier to operate.
The operational simplicity matters. You can run serious production workloads without turning infrastructure into its own project. With deployments at 100K+ requests per day on Docker Compose, simplicity is the advantage.
Below, you can see a code snippet that shows a sovereign AI stack under EU AI compliance:
# docker-compose.yml (sketch)
services:
vllm:
image: vllm/vllm-openai:latest
command: >
--model mistralai/Mistral-7B-Instruct-v0.3
--port 8000 --gpu-memory-utilization 0.9
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
n8n:
image: n8nio/n8n:latest
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
depends_on: [postgres]
qdrant:
image: qdrant/qdrant:latest
volumes: [qdrant_data:/qdrant/storage]
fastapi:
build: ./api
environment:
- VLLM_URL=http://vllm:8000
- LANGFUSE_HOST=http://langfuse:3000
depends_on: [vllm, langfuse, postgres]
langfuse:
image: langfuse/langfuse:latest
environment:
- DATABASE_URL=postgresql://...
postgres:
image: postgres:16
environment:
- POSTGRES_DB=app
volumes: [pg_data:/var/lib/postgresql/data]
keycloak:
image: quay.io/keycloak/keycloak:latest
command: start
caddy:
image: caddy:latest
ports: ["80:80", "443:443"]
volumes: [./Caddyfile:/etc/caddy/Caddyfile]Note that this is not the full production configuration. It is the shape of the EU-AI-compliant stack.
A real deployment would include secrets management, backups, monitoring, TLS configuration, retention policies, network rules, and environment-specific settings. But the core structure is visible here: inference, orchestration, retrieval, governance, application logic, identity, database, and gateway all run inside the same controlled environment.
On a fresh Hetzner box, this kind of sovereign stack can usually be running within 30–90 minutes. In a real customer engagement, the goal is to have the sovereign foundation live by the end of week one.
Posture B keeps the same overall architecture as Posture A. The difference is the inference layer.
Instead of running Mistral on Hetzner, FastAPI calls Claude through AWS Bedrock in Frankfurt. This gives you access to frontier-level reasoning while keeping the data path inside the EU inference profile, which is crucial for EU AI compliance.
That makes Posture B useful when you need stronger model capability, but your workload does not require the strictest sovereign setup.
AWS Bedrock in eu-central-1 — Frankfurt — can provide access to Claude models through the EU inference profile.
The important detail is the eu. prefix. With this profile, requests are processed only within six EU regions:
According to the original architecture logic, this region list is contractually defined and cannot be changed unilaterally by AWS.
That is the practical value of Posture B: you get frontier models without sending inference traffic to a US-only API.
As of the time of writing, the EU-AI-compliant Claude lineup available through Bedrock Frankfurt includes:
| Model | Best For | Cost / Capability Profile |
|---|---|---|
| Claude Haiku 4.5 | Classification, extraction, simpler structured tasks | Cheap and fast |
| Claude Sonnet 4.6 | Most production reasoning workloads | The default workhorse |
| Claude Opus 4.6 | Hardest reasoning tasks | Highest capability, highest cost |
Claude 4.7 is not included in this compliant setup because it is global-only at the time of writing and not yet available in EU regions for compliant deployment.
So the practical rule is simple: for compliant builds, design around Sonnet 4.6 and Opus 4.6, not a future model that may or may not be available in the right region.
The rest of the architecture stays almost similar. You still use the same core layers:
The main change is this:
vLLM is replaced by FastAPI calling AWS Bedrock via the Bedrock SDK and EU inference profiles.
That means the system still follows the same rule from the four-layer model: n8n does not call the model directly. n8n calls FastAPI. FastAPI controls the model call, routing, validation, tracing, and logging.
Posture B uses a pay-as-you-go token model.
That makes it easier to start because you do not need to buy or rent GPU capacity. At low volume, this is usually cheaper and simpler than self-hosting.
The cost logic is:
| Usage Pattern | Which Option Usually Wins |
|---|---|
| Low volume — under 1M tokens/day | Bedrock is usually cheaper |
| Medium volume | Bedrock remains convenient, but costs should be monitored closely |
| High volume | Sovereign GPU hosting often becomes cheaper |
From this point of view, the trade-off is predictable: no fixed GPU cost upfront, but your cost continues to scale with usage.
Also, note that Bedrock EU regional pricing usually carries a 5–10% premium over US pricing.
In this Posture, prompts and responses stay inside the six EU regions covered by the EU inference profile.
AWS’s DPA applies. Anthropic’s consumer or direct-provider DPA does not control this setup, because you are accessing Claude through Bedrock.
It is also important to note that Anthropic does not retain or train on prompts and outputs when Claude is accessed this way.
That distinction matters for your EU AI compliance because the governing relationship is with AWS Bedrock, not with Anthropic as a standalone API provider.
Although Posture B reduces data-transfer concerns, it does not remove all legal exposure.
Because AWS is a US-headquartered company, it means the CLOUD Act applies to AWS Inc. And as we've already mentioned above, the legal risk is real, even if the data is processed in EU regions.
However, this is not the same as using a US-only AI API. The EU inference profile is contractually limited to EU regions, and AWS cannot simply route the data somewhere else on its own. Notes that AWS states it will challenge CLOUD Act warrants for EU customer data and has done so.
So the position is balanced:
Posture B is not fully sovereign. But it is materially different from sending prompts directly to a US-hosted model API.
That is why it can be acceptable for many T2 and T3 workloads, but not for the strictest T1 cases.
Launched in January 2026 in Brandenburg under the region name eusc-de-east-1, the AWS European Sovereign Cloud is designed as a more sovereign AWS environment, operationally separate and run by AWS Europe with EU-only personnel. However, Claude is not available there at the moment of writing. That means it is important to separate the two ideas:
When Claude lands in AWS European Sovereign Cloud, it may become the highest-sovereignty Bedrock option for EU customers. Until then, strict sovereign workloads should default to Posture A.
Posture B gives you several advantages:
This is why Posture B is attractive for B2B SaaS, mid-market automation, internal productivity tools, and many standard enterprise workflows that are EU-AI-compliant.
The trade-offs are also clear:
So Posture B is not the “easy EU AI compliance answer.” It is the pragmatic frontier option. Use it when the workload justifies frontier capability, the data tier allows it, and the risk has been documented clearly.
Posture C is what most production deployments end up with when theory meets real workloads. It combines the two previous approaches:
As we’ve already mentioned, this approach offers EU AI compliance while giving you a practical balance: sovereign by default, frontier when justified.
In a hybrid setup, Mistral on Hetzner handles the bulk of inference. These are the tasks where self-hosted models are usually good enough and economically attractive:
For these workloads, Mistral 7B or Mixtral is often enough. You keep most processing inside the sovereign stack, reduce token spend, and avoid sending routine data through an external provider.
Claude on Bedrock Frankfurt is reserved for workloads where Mistral’s capability ceiling starts to show. These are usually tasks that require stronger reasoning, such as:
The point is to use Claude only when the workload earns it.
In Posture C, FastAPI is the routing layer. A single endpoint receives the request, checks the workload type and data tier, then decides whether the request should go to Mistral or Claude. The routing logic follows the same principle as the rest of this guide:
Data classification first, model choice second.
Here is the original router pattern in simplified form:
# Router pattern (sketch)
def route_request(prompt: str, task_type: str, data_tier: str) -> ModelResponse:
if data_tier == "T1":
# Sovereign-only. No Bedrock, no exceptions.
return mistral_call(prompt)
if task_type in ("extraction", "classification", "routing",
"summarization", "structured_output"):
return mistral_call(prompt)
if task_type == "complex_reasoning":
if data_tier in ("T2", "T3", "T4"):
return bedrock_claude_call(prompt, model="sonnet-4-6")
if task_type == "frontier_reasoning":
if data_tier in ("T3", "T4"):
return bedrock_claude_call(prompt, model="opus-4-6")
# Default sovereign
return mistral_call(prompt)Note that this is a pattern rather than production code. In a real implementation, the router also includes:
That registry matters because it turns routing into a controlled policy rather than a developer’s one-off decision.
Posture C is powerful because every workload has a documented route:
That creates a much cleaner compliance story, where you can clearly state:
This workload is T2. This task type requires complex reasoning. The approved route is Claude on Bedrock Frankfurt. The audit log records every call, etc.
This workload is T1. The approved route is Mistral on Hetzner only. No Bedrock path exists.
That is the practical value of the hybrid posture. It gives you flexibility without turning model choice into chaos.
Pure sovereignty is sometimes necessary when it comes to EU AI compliance. Pure frontier capability, on the other hand, is sometimes required for many business cases. Therefore, most real systems need both, because it’s the way to keep routine work cheap, controlled, and sovereign, combining it with hard reasoning when it clearly improves the result.
The frontend matters from the perspective of AI compliance in Europe, but not in the way many teams think. For an EU-compliant AI app, the frontend is rarely the hardest architectural decision. The harder questions are where inference happens, how data moves, how permissions work, and how audit logs are preserved. Still, the frontend is where users experience the system, so it needs to be reliable, maintainable, and compatible with your deployment posture.
The rule is simple: pick based on team capability, not framework hype. A familiar framework shipped correctly is better than a fashionable framework nobody on the team can maintain.
Below, you can see a practical comparison of frameworks suitable for EU AI compliance:
| Framework | Best When | EU Hosting |
|---|---|---|
| Next.js | Your team knows React. You need app-shell complexity, heavy interactivity, SSR, or ISR. | Vercel Frankfurt or Hetzner self-host |
| Nuxt | Your team knows Vue. You want server-rendered apps with a strong developer experience. The server-route-as-API pattern fits AI gateways well. | Hetzner self-host or NuxtHub on Cloudflare |
| Astro | The app is content-heavy: marketing pages, documentation, guides, or mostly static pages with small islands of interactivity. | Static EU hosting, Cloudflare Pages, Hetzner static |
| SvelteKit | You want smaller bundles than Next/Nuxt and a clean experience for AI dashboards. The ecosystem is slightly smaller, but the developer experience is strong. | Hetzner self-host |
| Remix | Your app is form-heavy and benefits from strong alignment with web platform fundamentals. | Hetzner self-host |
All five are good choices, and none of them is wrong if your team knows how to build with it. The wrong move, however, is rebuilding in a framework your team does not know because someone read one convincing blog post.
Now, let’s say a few more words about each framework.
Next.js is the obvious choice when you need an EU-compliant AI app, your team already works in React, and the product needs a rich application shell. It fits well for:
Its strength is ecosystem depth. You get mature libraries, hiring availability, and strong patterns for authentication, data loading, and UI complexity.
The trade-off is operational complexity. If you need strict sovereignty, hosting on Vercel may not be acceptable because Vercel is US-headquartered. In that case, self-hosting on Hetzner becomes the cleaner option that opens the path to EU AI compliance.
Nuxt is the natural option for Vue teams. It works well when you want a polished developer experience, server-rendered pages, and a clean structure for app routes, server routes, and API-like behavior.
For EU-AI-compliant apps, Nuxt can fit especially well when the frontend needs to communicate with internal backend services without turning the architecture into a mess. Its server-route pattern can sit nicely beside a FastAPI gateway, depending on how your team wants to split responsibilities.
Hosting is flexible, which is also an important advantage. You can self-host on Hetzner for stronger control or use NuxtHub on Cloudflare as a middle ground.
Astro is the best choice when the website is mostly content. It means that it is the best option for EU AI compliance in the following areas:
Astro ships very little JavaScript by default, which keeps pages fast and simple. That matters if the site is primarily designed to explain the product, rank in search, convert leads, or host a large knowledge base.
It is usually not the first choice for a deeply interactive AI application. But for the content and documentation layer around an AI product, Astro is excellent.
SvelteKit is a strong option when you want a modern app framework with smaller bundles and less frontend overhead. It can work well for EU-AI-compliant:
Compared with Next.js and Nuxt, the ecosystem is smaller. That does not make it worse, but it means you should choose it when the team is comfortable with Svelte and does not depend heavily on React- or Vue-specific libraries.
Remix is a good fit when your AI app depends heavily on forms, submissions, approvals, edits, and state changes that map cleanly to web platform patterns. That makes it useful for:
It is less about visual flash and more about clean request/response behavior, progressive enhancement, and reliable data handling important for EU AI compliance.
It is also important to mention that hosting choice is flexible for ordinary T3 or T4 workloads. But when it comes to stricter workloads, it becomes part of the compliance story. So, here are a few important aspects to stay compliant with AI rules in Europe:
This does not mean Vercel or Cloudflare are “bad.” It means the hosting choice must match the workload tier and customer risk profile for the sake of EU AI compliance. Just keep in mind that a frontend serving public marketing pages does not need the same posture as a portal showing sensitive employee, medical, or financial data.
A useful way to decide is to separate the frontend into product surfaces:
| Product Surface | Best-Fit Options | Why |
|---|---|---|
| Marketing website | Astro, Next.js, Nuxt | SEO, speed, content structure |
| Documentation hub | Astro, Nuxt, Next.js | Content-heavy, easy navigation |
| Internal AI dashboard | Next.js, SvelteKit, Nuxt | Interactivity, state, charts, permissions |
| Human review queue | Remix, Next.js, Nuxt | Forms, approvals, workflow state |
| Chat interface | Next.js, Nuxt, SvelteKit | Streaming UI, authenticated sessions, app shell |
| Customer portal | Next.js, Nuxt, Remix | Auth, account data, workflow interaction |
This is often more useful than trying to pick one framework for everything. In larger projects, the marketing site and the authenticated application do not always need the same frontend stack.
And the final point is that the frontend choice should reduce project risk, not add a new one. All five frameworks are good for AI regulation in Europe. You need to choose the one your team can ship, secure, host, and maintain under the compliance posture your workload requires.
From the standpoint of EU AI compliance, the database is not just a place where your app stores records. It is where many of the most important guarantees should live: permissions, validation rules, audit trails, eligibility logic, calculations, and the guardrails that decide what data can move into an AI workflow. If these rules are scattered across frontend code, n8n workflows, Python services, and configuration files, the system becomes hard to change and even harder to audit. Postgres gives you a cleaner foundation: one place where business logic can be enforced close to the data, versioned with migrations, and explained when a customer, DPO, or auditor asks how the system actually works.
Most AI app architectures often share the same mistake: business rules end up everywhere. One rule lives in the application code, another sits inside an n8n workflow, a third hides in the frontend, and so on. With this architecture, changing a single rule often results in updating more than one place, and when someone asks for an audit trail, there is no way you can point to a single source of truth. The fix is pretty straightforward:
Put business logic in Postgres.
However, not all business logic belongs there, such as model prompts, UI rendering, long-running workflow orchestration, etc. But rules that define eligibility, scoring, validation, calculations, and derived values should live close to the data. There are three reasons why this works especially well for EU-compliant AI systems.
The real value is that Postgres does not just store the data but also protects the rules around it. For EU AI compliance, this matters because your system needs to prove how decisions were made, who had access, what data was eligible for processing, and which controls were applied. When those guarantees live in Postgres, the audit surface becomes smaller, clearer, and harder to bypass.
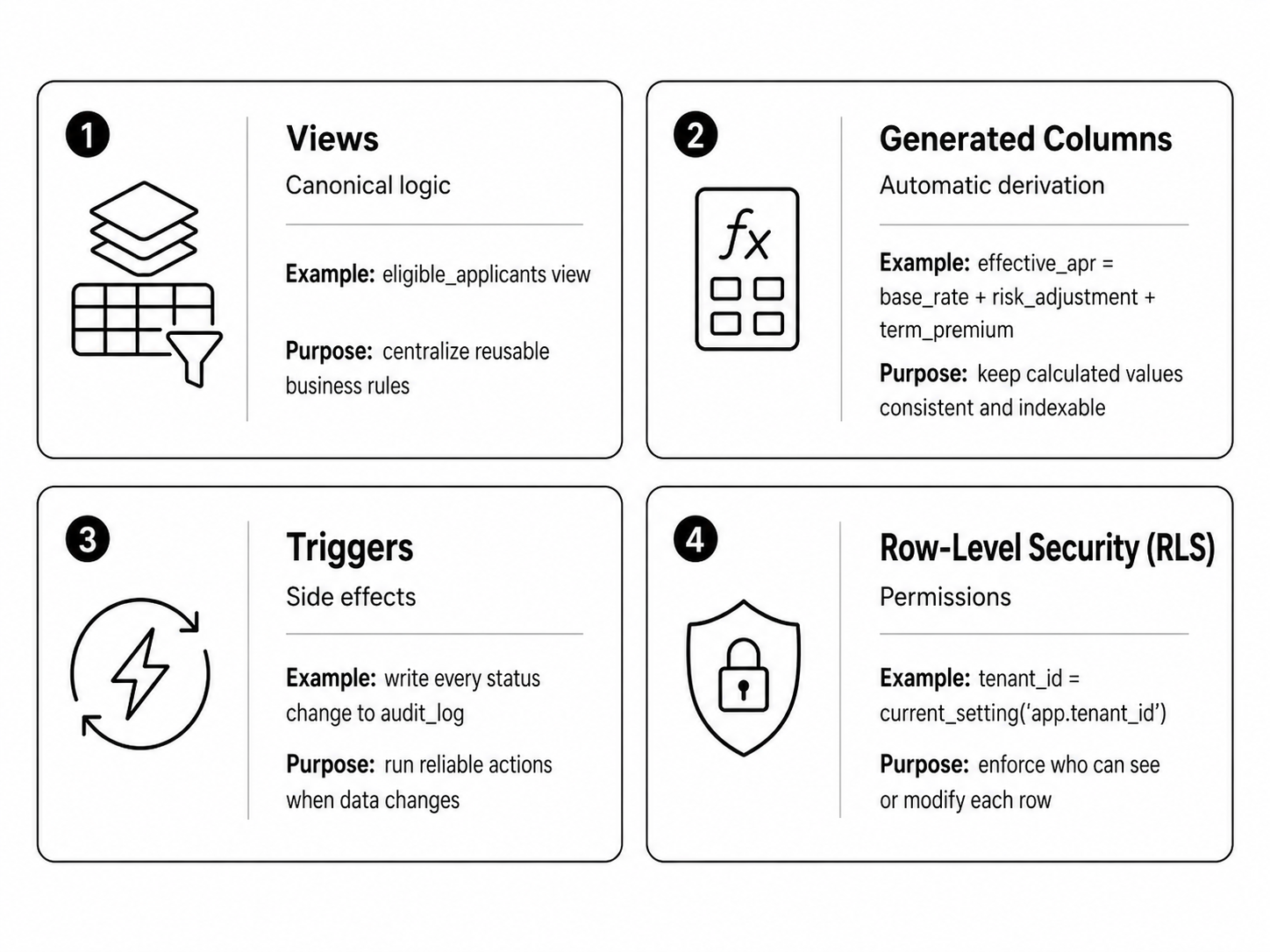
Once business logic moves closer to the data, you need to figure out which Postgres features carry which responsibilities. The good news is that you do not need any exotic database tricks. Most compliant AI workflows can be made cleaner and safer with four familiar tools: views, generated columns, triggers, and Row Level Security.
A view is a saved SELECT. It gives you one reusable definition of a business rule, report, or filtered dataset.
Use views for:
Note that a materialized view is different because it stores the result instead of recalculating it every time. Use materialized views for heavier reads where speed matters more than real-time freshness, such as:
A generated column is calculated automatically from other columns.
Use generated columns for values that should never drift from their source data:
The advantage is simple: Postgres computes the value on insert or update. You can index it, the application can read it, but the application cannot accidentally write the wrong value into it.
A trigger runs automatically when data is inserted, updated, or deleted.
Use triggers for actions that must happen reliably alongside a data change:
Please, note this important detail: triggers run inside the same transaction. If the trigger fails, the original change rolls back too. That makes them safer than application-level event publishers, where one part can succeed while the other silently fails.
Row Level Security, or RLS, lets Postgres enforce who can see or modify specific rows.
From the perspective of an EU-compliant AI app, you should use RLS for:
Once RLS is on, application code cannot accidentally show one customer's data to another, because the database refuses. This is the kind of guarantee EU AI Act Article 14 (human oversight) and Article 15 (accuracy and robustness) want to see.
Once Postgres becomes part of your compliance architecture, hosting matters for EU AI compliance because the database may contain customer records, audit logs, workflow state, permission rules, and business logic. So the question is which Postgres option fits the workload tier.
There are three practical choices for EU deployments that can work. The difference is how much operational control and sovereignty your project requires.
| Option | EU Hosting | Best For | Watch Out For |
|---|---|---|---|
| Supabase EU | Frankfurt available; Supabase Inc. is US-headquartered, so CLOUD Act exposure applies | MVPs, B2C apps, internal tools, prototypes that may scale | Not suitable for strict T1 sovereignty requirements. Migration cost when you outgrow it. |
| Neon EU | Frankfurt available; Neon Inc. is US-headquartered | Serverless workloads, scale-to-zero apps, branching for dev/staging | Same sovereignty caveat as Supabase. Performance tuning may be needed at scale. |
| Self-hosted on Hetzner | Frankfurt, Falkenstein, or Nuremberg; Hetzner is German | Production at scale, sovereign-strict customers, full control over Postgres version and extensions | You operate it yourself: backups, replication, upgrades, monitoring. |
Supabase EU and Neon EU are both strong products. They solve problems you probably do not want to solve early: connection pooling, point-in-time recovery, branch databases, real-time features, generated client libraries, and developer-friendly workflows. For a small team building an MVP, they can easily save hundreds of engineering hours.
The trade-off, however, is sovereignty, which may be crucial for EU AI compliance. Both Supabase Inc. and Neon Inc. are US-headquartered companies. Even when the database runs in Frankfurt, CLOUD Act exposure still exists at the company level. From the perspective of EU AI compliance, both options are usually acceptable for T3 and T4 workloads. For T1 workloads, they are not.
Self-hosted Postgres on Hetzner gives you the strongest control because you can choose the Postgres version, install the extensions you need, such as pgvector, pgcrypto, pg_partman, pg_stat_statements, or pg_audit, configure replication, backups, monitoring, and upgrades, and so on. The operational burden is real, but manageable. In the original estimate, once stable, it usually means around 4–8 hours per month of database operations.
The important insight is that the application code does not need to change much across these options. The same Postgres-as-business-logic patterns work on Supabase EU, Neon EU, and self-hosted Hetzner Postgres. That gives you a practical migration path: start on Supabase or Neon when speed matters, then move to Hetzner when sovereignty pressure increases. The migration is still real — think a long weekend, not a button click — but the app itself should not need to be rewritten.
Another value of Postgres is that it can enforce rules that prevent entire classes of bugs, data leaks, and compliance failures. Below, you can find simple database-level guardrails that belong in almost every serious EU-AI-compliant app.
Every multi-tenant table should carry a tenant_id, and Row Level Security should enforce that boundary on every read and write.
-- Every multi-tenant table:
CREATE TABLE invoices (
id uuid PRIMARY KEY,
tenant_id uuid NOT NULL,
...
);
-- RLS policy enforces tenant boundary on every read/write
ALTER TABLE invoices ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON invoices
USING (tenant_id = current_setting('app.tenant_id')::uuid);The application sets app.tenant_id at session start based on the authenticated user’s tenant. After that, no SQL query anywhere in the system can leak data across tenants — not from the app, not from n8n, not from Dagster jobs. The database refuses, which is extremely important for EU AI compliance.
Audit logs should be stored in a dedicated table and protected from updates or deletes to maintain compliance with AI legislation in Europe. You can achieve it as follows:
CREATE TABLE audit_log (
id bigserial PRIMARY KEY,
occurred_at timestamptz NOT NULL DEFAULT now(),
actor_id uuid NOT NULL,
action text NOT NULL,
entity_type text NOT NULL,
entity_id uuid,
before jsonb,
after jsonb,
context jsonb
);
-- Append-only — no UPDATE, no DELETE allowed
REVOKE UPDATE, DELETE ON audit_log FROM PUBLIC;
REVOKE UPDATE, DELETE ON audit_log FROM app_user;
-- Triggers on key tables write here automaticallyThis is the foundation for EU AI Act Article 12 logging. Every relevant change is recorded. The application cannot quietly edit the log later. What’s even more important is that an attacker with application-level access cannot simply delete the evidence. Retention can then be handled through partitioning and partition pruning.
From the perspective of the European AI regulation, some rules should not live in the application code. The database itself should enforce them, as the following code shows:
-- An invoice cannot be paid before it's issued
ALTER TABLE invoices
ADD CONSTRAINT issued_before_paid
CHECK (paid_at IS NULL OR paid_at >= issued_at);
-- A claim cannot exceed the policy maximum
ALTER TABLE claims
ADD CONSTRAINT amount_within_policy
CHECK (amount <= (SELECT max_amount FROM policies WHERE id = policy_id));
-- An applicant cannot be both approved and rejected
ALTER TABLE applications
ADD CONSTRAINT decision_consistency
CHECK ((approved_at IS NULL) OR (rejected_at IS NULL));Each constraint captures a business rule that cannot be skipped by another code path. If the rule lives only in application code, a different service, workflow, or import job can bypass it. However, as a database constraint, it applies everywhere.
Eligibility logic should live in one place rather than be recreated in every service. See the snippet below:
CREATE VIEW eligible_applicants AS
SELECT a.*
FROM applicants a
JOIN credit_scores cs ON cs.applicant_id = a.id
WHERE cs.score >= 650
AND a.income_verified = true
AND a.kyc_completed_at IS NOT NULL
AND a.kyc_completed_at > now() - interval '12 months'
AND NOT EXISTS (
SELECT 1 FROM rejections r
WHERE r.applicant_id = a.id
AND r.created_at > now() - interval '6 months'
);Now the eligibility rule has a single SQL definition that auditors can read, and compliance can approve. Application code only needs to query eligible_applicants, and the rules cannot be applied differently in different parts of the system.
Another Postgres guardrails that prevent AI compliance failures states that generated columns are useful when calculations must be consistent every time. Just look at this code example:
-- Calculate effective interest rate as a generated column
ALTER TABLE loan_offers
ADD COLUMN effective_apr numeric
GENERATED ALWAYS AS (
base_rate + risk_adjustment + term_premium
) STORED;
CREATE INDEX ON loan_offers (effective_apr);With this snippet, the effective APR is calculated by Postgres, indexed for queries, and impossible for the application to set incorrectly. The app reads the value but never writes it, which may be required from the perspective of EU AI compliance.
This guardrail matters specifically for the compliance of AI apps in the EU. Before anything goes to a model, you need to validate it through a Postgres view as follows:
-- A view that returns only well-formed prompts ready for inference
CREATE VIEW ready_for_inference AS
SELECT
i.id,
i.workflow_type,
i.input_payload,
i.tenant_id
FROM inference_queue i
WHERE i.input_payload ? 'document_text'
AND length(i.input_payload->>'document_text') BETWEEN 50 AND 100000
AND i.input_payload ? 'task_type'
AND i.input_payload->>'task_type' IN ('extract', 'classify', 'summarize')
AND NOT i.input_payload ? 'pii_detected'
AND i.created_at > now() - interval '1 hour';FastAPI reads from this view, so if an item does not appear here, it is not eligible for inference. It results in PII-tagged inputs being filtered out, stale inputs being ignored, and invalid task types never reaching the model gateway.
This makes the AI layer safer by default: the model cannot accidentally process bad input because the database never exposes it. What’s even more important from the perspective of both EU AI compliance and security, the pattern compounds. Once you have ten guardrails like this in Postgres, the space for bugs becomes much smaller. At the same time, you end up with a simpler model gateway, a cleaner audit story, and compliance documentation that is much easier to produce.
Once the data layer is under control, EU AI compliance depends on what happens between systems: how a request enters the workflow, how it reaches the model gateway, how errors are handled, how retries work, and how every important action gets logged. This is the glue that keeps your AI app from becoming fragile.
While a prototype can survive with a few direct API calls, a production system needs orchestration, validation, audit trails, failure handling, and clear ownership. In this section, we’ll look at the workflow layer — n8n, FastAPI, retries, dead-letter queues, idempotency, and audit logs — and explain how they turn an AI feature into a reliable business process.

Once the architecture is split into clear layers, you still need one system that moves work between them. That is where n8n fits.
In this blueprint, n8n is the workflow engine. It listens for triggers, moves data between systems, calls FastAPI endpoints, routes items for human review, writes results back to business tools, and handles operational exceptions.
From the perspective of EU AI compliance, the important part is the deployment model: self-hosted in the EU.
Most popular automation platforms — Zapier, Make, Workato, and similar tools — are SaaS-first. They are convenient, but they often introduce data residency and cross-border processing questions. For simple marketing automations, that may be fine. For AI workflows touching personal data, customer records, documents, invoices, HR data, or regulated business processes, it becomes harder to justify.
Self-hosted n8n avoids that problem. You can run it on Hetzner, connect it to your Postgres database, keep workflow state inside the EU, and make it part of the same compliance boundary as the rest of the system.
n8n works well here because it sits between two worlds: business workflows and technical systems.
It is visual enough for teams to understand what is happening, but flexible enough for engineers to extend when needed. It can trigger workflows from webhooks, schedules, queues, emails, forms, or external systems. It can call APIs, write to databases, send notifications, update CRMs, and route exceptions.
In practice, this makes it a good orchestration layer for AI apps in Europe. The main reasons are pretty much straightforward:
n8n should own orchestration. That means it should answer questions like:
At the same time, it is crucial that n8n doesn’t own core business logic and doesn’t call LLMs directly. There is a clear separation:
While n8n triggers and coordinates the workflow, FastAPI controls the AI logic, and Postgres enforces the rules.
So instead of placing prompts, model calls, PII filtering, output validation, and routing rules inside n8n nodes, the workflow calls a FastAPI endpoint such as:
POST /infer/extract
POST /infer/classify
POST /infer/summarize
POST /workflow/validate
POST /review/createFastAPI then prepares the prompt, chooses the model, validates the response, traces the call in Langfuse, and returns a structured result to n8n. This keeps workflows readable as well as prevents every n8n workflow from becoming its own half-hidden AI application.
As we’ve already mentioned, n8n becomes the glue when it comes to production. A typical document workflow might look like this:
You can clearly see the pattern when n8n moves the work, and other layers handle specialized responsibilities. Now, let’s look at the core components of the glue.
Every production n8n workflow should have a sibling error workflow. When something fails, the error workflow catches it, records what happened, and alerts the right people. The failure should not disappear inside an execution log nobody reads.
A good error workflow should:
For EU AI systems, this is far more than just operational hygiene, because it supports traceability. If a workflow fails while processing regulated data, you can easily understand what failed, when, why, and whether the item was retried or reviewed manually.
Idempotency prevents the same event from being processed twice. This matters because real systems retry things. For instance, webhooks fire again, network requests time out, external platforms send duplicates, a user uploads the same file twice, and so on. Take idempotency out of the equation, and the same invoice could be processed twice, the same customer could receive two messages, or the same workflow could create duplicate records.
The practical pattern to address this problem is simple:
This makes retries safe.
In this AI system, there is also a special place for failed items. A dead-letter queue is where items land after they fail too many times or cannot be processed safely. In this EU-AI-compliant architecture, that queue can be a Postgres table such as review_queue or failed_jobs.
To give human operators a clear place to review stuck work, each item should include:
This is how you avoid silent automation failures. It also gives you a better audit trail for decisions that require manual intervention — something crucial for EU AI compliance.
Another essential aspect is that not every failure needs human review immediately, simply because some failures are temporary: an API is down, a database connection resets, a third-party system times out, or a model endpoint returns a transient error.
For these cases, n8n should retry the step automatically. The default pattern is 3–5 retries with exponential backoff. That means the workflow waits longer between each attempt instead of hammering a failing service repeatedly.
If retries succeed, the workflow continues. If retries fail, the item goes to the dead-letter queue.
This keeps temporary issues from becoming manual work, while still surfacing persistent problems quickly.
Also, note that every important n8n execution should write to the central Postgres audit log. You cannot afford a system that only relies on n8n’s internal execution history only. It is useful for debugging, but it should not be your primary EU AI compliance record.
Therefore, your audit log should capture the following details:
For high-risk AI systems, this directly supports the logging expectations under the EU AI Act Article 12. For GDPR, it also helps prove what data moved where and why.
Let’s say it again: you should never call models directly from n8n. That rule may sound strict at first, but it solves one of the biggest problems in production AI systems: scattered model logic. If every workflow calls the model on its own, every workflow also starts managing prompts, validation, retries, fallbacks, tracing, and PII controls in its own way. That becomes messy fast — and it creates unnecessary risk for EU AI compliance. A cleaner pattern is simple:
n8n calls FastAPI. FastAPI calls the model.
In this architecture, FastAPI becomes the LLM gateway — the controlled layer between business workflows and model providers.
It is tempting to call OpenAI, Claude, Mistral, or Bedrock directly from an n8n HTTP node. It works in a demo. It can even work for a small internal prototype. But production is different.
Once the workflow handles real data, especially personal data, you need one place to manage the AI logic properly, and FastAPI gives you that place. This is important because FastAPI controls:
FastAPI does not need to become a huge application. In the original blueprint, the FastAPI layer is usually small — around 200–500 lines of Python per customer engagement. It exposes clear endpoints such as:
POST /infer/extract
POST /infer/classify
POST /infer/summarizeWhile n8n calls these endpoints, FastAPI receives the request, validates the input, builds the prompt, routes the call to the right model, records the trace in Langfuse, and returns a structured response. This keeps n8n clean and AI logic testable.
FastAPI is also where several compliance-critical controls come together:
That makes FastAPI the load-bearing wall of the AI app.
Without it, every workflow becomes a small, ungoverned model client. With it, model access becomes controlled, observable, and easier to defend under any AI regulation in Europe: either it is GDPR for AI, the EU AI Act, or the EU AI Act and GDPR together.
We’ve already covered these patterns in the previous sections. But for a production AI app, they are too important to leave scattered across the architecture. Here they are as one checklist, showing what every production AI app should include:
This is the difference between an AI workflow that works in a demo and one that survives production and withstands EU AI compliance regulations. If you can log what happened, retry what failed, prevent duplicates, and route unresolved cases to humans, the system becomes much easier to operate and, what’s also essential, much easier to defend during an audit.
For EU AI compliance, anonymization is not a magic escape hatch. It is a technical safeguard that only matters when you understand its limits. When a cross-border model call becomes genuinely necessary, it is crucial to understand what kind of masking is legal, what risk does it reduce, and what evidence do you need for the DPIA. Below, we focus on where anonymization fits, where it does not, and which tools make the most sense in production.
We have already touched on this earlier, but it is worth stating clearly once again: most workloads do not need a US frontier model.
For the majority of production AI tasks, Mistral is enough. Extraction, classification, routing, summarization, structured generation, and many RAG workflows can stay inside the EU without sacrificing the result that actually matters to the business.
There are only a few cases where sending data to Claude, GPT, or Gemini may become a serious option — and only when that data is not eligible for a cleaner EU-based route:
The first case does not require anonymization because you are not processing customer data. For the others, the order of preference should stay practical: first, try to get the customer comfortable with Bedrock Frankfurt and the EU inference profile. In many cases, that solves the problem. If not, test whether Mistral Large 2 is good enough. Only after that should anonymization enter the conversation.
That is the key point: anonymization is the last resort, not the default architecture.
This way, you can reduce risk when cross-border AI calls are unavoidable. However, it should not become an excuse to send data abroad before you have explored the simpler, safer options.
This is one of the most important legal distinctions in the whole guide. Get it wrong, and your DPIA can fall apart. So, let’s figure out the difference.
Under GDPR, anonymization means the data has been changed so completely and irreversibly that the person can no longer be identified. If the data is truly anonymized, it is no longer personal data and falls outside GDPR scope.
Pseudonymization is different. It means personal data has been processed so it can no longer be linked to a specific person without additional information. But if that additional information still exists somewhere — for example, in a mapping table — the data remains personal data under GDPR.
That matters to EU AI compliance because many “anonymization” patterns used in AI systems are actually pseudonymization.
For example, if Presidio replaces a real name with a fake name and stores the original-to-fake mapping in Redis, the process is reversible. If OpenAI Privacy Filter produces placeholders that can later be restored, the process is reversible too. These are useful risk-reduction techniques, but they are not true anonymization.
So the legal conclusion is simple: pseudonymized data still falls under GDPR.
That means cross-border transfer rules still apply, and being AI-Act- and GDPR-compliant is associated with a legal basis under Article 6, Standard Contractual Clauses, adequacy, or another valid transfer mechanism where relevant, documenting the processing in your DPIA, and so on.
The honest way to explain this to a customer is to explain that you pseudonymize before crossing the border. This reduces risk and is documented as a technical measure in the DPIA. However, it does not remove the processing from GDPR scope.
That framing is safer, clearer, and much easier to defend than pretending pseudonymization makes the data legally anonymous.
Microsoft Presidio is the most established open-source toolkit for detecting and removing personal information before data reaches an LLM. It is Apache 2.0 licensed, maintained by Microsoft, and has been used in enterprise environments since 2018.
For teams working on compliance with the EU AI Act and GDPR in terms of cross-border AI workflows, Presidio is usually the default starting point. Not because it solves every legal problem — it does not — but because it gives you a practical, production-tested way to detect and pseudonymize personal data before sending text into a model.
The architecture is simple. Presidio has two main services:
The common production pattern is reversible pseudonymization. Presidio replaces real personal data with realistic fake values, stores the original-to-fake mapping, sends the sanitized text to the LLM, and then restores the original values in the model response when needed. LangChain wraps this pattern as PresidioReversibleAnonymizer.
This is what many production cross-border AI calls use. It is not true anonymization, as explained above. It is pseudonymization — a risk-reduction measure that still needs to be documented under GDPR.
Presidio is strong because it is practical. In short, Presidio does three things well: it detects common PII, it lets you extend detection rules, and it fits cleanly into production infrastructure. Now, let’s add some clarity.
Presidio works well for standard personal data detection, especially in English-language text. English PII recall at roughly 96% on standard PII makes it good enough for many business workflows, especially when paired with testing and human review for sensitive use cases.
Another advantage is extensibility. If Presidio does not detect a certain identifier, you can write a custom recognizer. Usually that means defining a regex pattern, adding checksum logic where needed, and registering it with the analyzer. This is very useful for European AI apps because many local identifiers are not covered well by default.
Presidio is also easy to deploy. Microsoft publishes Docker images, so you can run it as part of your own infrastructure instead of calling a third-party redaction API. That matters for GDPR for AI and overall EU AI compliance, because the redaction layer itself may process sensitive data.
It also integrates well with the broader AI stack. You can use it with LangChain, LiteLLM, custom Python services, FastAPI middleware, or your own gateway layer. In the architecture we provide in this guide, Presidio usually sits in or near FastAPI, before the request reaches Claude, Mistral, or another model.
The problem is that Presidio is not an almighty solution. You can consider it a strong foundation, but it’s far from being a finished EU compliance layer, and here is why.
Presidio is not Europe-ready out of the box. Its default recognizers are heavily oriented toward common and US-style identifiers. For EU deployments, you almost always need additional recognizers. Otherwise, important identifiers can pass through undetected.
Typical EU-specific entities you may need to add include:
This is where teams often underestimate the work. Adding a recognizer is not difficult, but doing it properly takes time. The original estimate is 9–17 hours per identifier when you include research, regex design, checksum logic, tests, and validation against real examples.
For a German fintech that needs IBAN, BIC, Steuer-ID, Handelsregisternummer, and EU driving license detection, that can quickly become 50–80 engineering hours. And the work does not end there. Formats change, edge cases appear, and false positives need tuning.
This is the gap commercial tools often exploit. They offer broader entity libraries, more languages, and less setup work. In a custom sovereign stack, the practical answer is usually to maintain a private Presidio extension repository per region or vertical.
Presidio’s named entity recognition backend is configurable, and this matters a lot for European deployments. If you process German text but keep the default English-oriented setup, PII detection quality drops. Names, addresses, locations, dates, and document patterns behave differently across languages. The model needs to understand that context.
For German-language workflows, use spaCy’s de_core_news_lg model. For multilingual workflows, configure both German and English models, then route by detected language.
The original draft gives a clear improvement: switching from the English-default model to the German-trained spaCy model can raise German PII recall from roughly 40% to 85%.
The important part is that this is mostly configuration, not a complete rebuild. You do not need to change your whole anonymization architecture. You need to configure Presidio with the right NLP models and make language detection part of the pipeline.
That one change can make the difference between a redaction layer that looks good in a demo and one that actually works on German business documents.
In this architecture, Presidio usually runs as a FastAPI middleware service on Hetzner.
It exposes three simple endpoints:
/analyze
/anonymize
/deanonymizeThe service itself can remain stateless. The reversible mapping — original value to fake value — lives in Redis with a short TTL. 60 seconds is the typical request lifetime: long enough for the LLM round-trip, short enough to avoid keeping personal data around if something fails. The workflow looks like this:
And here is the original production pattern:
from langchain_experimental.data_anonymizer import PresidioReversibleAnonymizer
anonymizer = PresidioReversibleAnonymizer(
analyzed_fields=[
"PERSON", "EMAIL_ADDRESS", "PHONE_NUMBER",
"IBAN_CODE", "LOCATION", "DATE_TIME",
"STEUER_ID", "HANDELSREGISTERNUMMER" # custom recognizers
],
languages_config={
"nlp_engine_name": "spacy",
"models": [
{"lang_code": "de", "model_name": "de_core_news_lg"},
{"lang_code": "en", "model_name": "en_core_web_lg"}
]
}
)
# Anonymize → call LLM → deanonymize
sanitized = anonymizer.anonymize(original_text)
response = await claude_client.invoke(sanitized)
restored = anonymizer.deanonymize(response.content)This is one of the most common patterns for cross-border AI calls: sanitize first, call the model, restore afterward.
And from the perspective of EU AI compliance, we should once again emphasize that this does not magically make the data anonymous. It reduces exposure before the model call and creates a technical safeguard you can document in the DPIA.
OpenAI Privacy Filter is a much newer option in the PII detection and redaction space. It was released on April 22, 2026, under the Apache 2.0 license, and is available on Hugging Face under the openai/privacy-filter repository.
The important difference is how it works. Presidio is mostly rule-based, with optional NER support. OpenAI Privacy Filter is a small language model built specifically for token-level PII detection. It reads the input and labels each token as either non-PII or one of several private-data categories.
For EU AI compliance, this is interesting because many privacy failures are contextual, meaning that a date is not always sensitive, a URL is not always private, a name might be public in one document and sensitive in another, etc. Rule-based tools can struggle with that nuance. A model-based detector can sometimes understand the surrounding context better.
However, that does not make OpenAI Privacy Filter a replacement for Presidio. At least, yet. What you can do now is treat it as a strong additional layer rather than the only thing standing between personal data and a cross-border model call.
OpenAI Privacy Filter is a 1.5-billion-parameter Mixture-of-Experts model with around 50 million active parameters. In practical terms, it is much smaller than a general-purpose frontier model, but large enough to make context-aware judgments about sensitive information.
Instead of generating a response, OpenAI Privacy Filter scans the input and marks which tokens belong to specific PII categories. It can process up to 128K tokens of context in a single pass, which makes it especially relevant for long documents, contracts, reports, and internal knowledge files.
The model currently detects the following eight categories:
The reported benchmark performance is strong: 96% F1 on the PII-Masking-300k benchmark out of the box, and 97.43% on a corrected version of that benchmark.
That said, benchmarks are not production guarantees. For real AI GDPR workflows, you still need testing against your own documents, your own languages, and your own domain-specific identifiers.
The main difference between OpenAI Privacy Filter and Presidio is the detection approach. Presidio looks for entities using NER, regex patterns, checksum validation, and custom recognizers. OpenAI Privacy Filter uses a small language model to classify tokens based on context. That changes the trade-offs. Let’s compare the two solutions side by side in a table:
| Dimension | Presidio | OpenAI Privacy Filter |
|---|---|---|
| Detection Method | NER + regex + checksum | Small LLM with token classification |
| Context Awareness | Limited to recognizer scope | Strong; sees up to 128K tokens |
| Customization | Add a regex, register a recognizer | Fine-tune the model on your domain |
| EU Identifier Coverage | Custom recognizers needed, often 50–80 hours for a realistic EU set | Account numbers include IBANs natively; named-entity flexibility helps |
| Compute | CPU, fast, low memory | 3GB VRAM in FP16, or 4–8GB RAM on CPU; slower than Presidio |
| Maturity | Production-stable since 2018 | Released April 2026; production tracking required |
The practical difference is that Presidio is easier to control, easier to explain, and more mature, while OpenAI Privacy Filter is better positioned for context-heavy detection where fixed rules may miss something.
For example, Presidio is usually stronger when you know exactly what to look for: IBAN, Steuer-ID, VAT number, phone number, email address, account number. You can write recognizers, test them, and explain the logic.
OpenAI Privacy Filter becomes more interesting when the sensitivity depends on context: a date of birth hidden in a paragraph, a private URL inside an internal support ticket, a person’s name that matters only because of the surrounding text, or a credential-like value that does not match a simple pattern.
That is why the two tools should not be framed as enemies. In a serious AI setup compliant with the EU legislation, they can complement each other. Therefore, the safest position is:
Use OpenAI Privacy Filter as a complement to Presidio, not as a replacement — at least for the next 12 months.
By mid-2027, it should be clearer whether it matures into a full Presidio alternative or remains a specialized second-pass tool for context-aware detection.
There is also an important legal and compliance point. OpenAI describes Privacy Filter as a redaction and data-minimization aid, not as an anonymization, compliance, or safety guarantee. That framing matters.
Like Presidio, it supports risk reduction. It does not remove your GDPR obligations by itself. If the process is reversible, or if the remaining context can still identify a person, you are still dealing with personal data.
For EU AI compliance, the conclusion is straightforward: OpenAI Privacy Filter can improve your privacy layer, especially for hard-to-detect PII, but it should sit inside a broader system that includes workload classification, DPIA documentation, gateway controls, audit logs, and clear rules for when cross-border AI calls are allowed.
LiteLLM is a unified gateway for LLM APIs in your EU-AI-compliant stack. Instead of integrating every model provider separately, you put LiteLLM in front of them and talk to one OpenAI-compatible interface.
In practice, this means one gateway can route requests to OpenAI, Anthropic, Mistral, AWS Bedrock, Google Vertex, and more than 100 other providers. For EU AI compliance, that matters because model access should not be scattered across workflows, services, and one-off scripts. You want one controlled place where routing, guardrails, limits, and logging can happen.
LiteLLM is especially useful in hybrid deployments, where some workloads stay on Mistral and others go to Claude on Bedrock Frankfurt. Instead of hardcoding every provider path inside FastAPI, LiteLLM can become the model gateway underneath it.
There are two main reasons to consider LiteLLM.
First, LiteLLM has built-in Presidio integration as a guardrail. You can configure Presidio to run before the model call, define confidence thresholds, choose which entity types to detect, and mask sensitive values before the request reaches the LLM. The response can then be deanonymized afterward when needed.
That is useful for AI GDPR workflows because PII filtering becomes part of the gateway, not something each workflow has to remember to do manually.
Second, LiteLLM gives you one API surface for the Posture C routing pattern. In a hybrid architecture, that means you can define model aliases such as workhorse and frontier, then route requests through configuration instead of custom code spread across the app. For instance, like in this pattern:
# litellm config (sketch)
model_list:
- model_name: workhorse
litellm_params:
model: ollama/mistral:7b-instruct
api_base: http://vllm:8000/v1
- model_name: frontier
litellm_params:
model: bedrock/eu.anthropic.claude-sonnet-4-6-20250214-v1:0
aws_region_name: eu-central-1
guardrails:
- guardrail_name: presidio-pii
litellm_params:
guardrail: presidio
mode: pre_call
presidio_score_thresholds:
EMAIL_ADDRESS: 0.6
PERSON: 0.6
IBAN_CODE: 0.8
pii_entities_config:
EMAIL_ADDRESS: MASK
PERSON: MASK
IBAN_CODE: MASKNote that this is not a full production configuration. However, it shows the shape: one model alias for routine work, one for frontier reasoning, and a Presidio guardrail that runs before the call. With this setup, the application can call a stable model name like workhorse or frontier, while the actual provider configuration remains behind the gateway.
The trade-off is that LiteLLM adds another service to the stack. That is not automatically bad, but it matters. More services mean more deployment, monitoring, upgrades, configuration, and failure handling. For minimal stacks, FastAPI plus direct provider SDKs is often simpler and gives you more control.
If you use only one or two models, LiteLLM may be unnecessary. FastAPI can call Mistral or Bedrock directly and keep the routing logic readable.
LiteLLM becomes more attractive when the model layer gets more complex — especially when you have five or more models in active rotation, multiple providers, tenant-specific routing rules, or frequent model swaps.
So the decision rule is simple:
Use FastAPI directly for small stacks. Add LiteLLM when model routing becomes a platform problem.
That keeps the architecture practical instead of over-engineered.
Now, let’s finalize everything about the anonymization layer on the example of a Posture C deployment with cross-border model calls. It usually looks like this:
| Layer | Tool | Purpose |
|---|---|---|
| Detection | Presidio + spaCy de_core_news_lg + custom recognizers | Identify PII in input text |
| Pseudonymization | Presidio Anonymizer with Faker | Replace PII with realistic fake values |
| Mapping Store | Redis with TTL = 60s | Hold the original-to-fake mapping for response deanonymization |
| Gateway | FastAPI or LiteLLM | Route to the correct model, instrument calls with Langfuse, enforce rate limits |
| Audit | Postgres audit_log table | Record every anonymization and LLM call for DPIA evidence |
The key point is that LiteLLM supports the compliance architecture rather than replacing it.
You still need workload classification, a DPIA, audit logs, clear rules for when data may leave the sovereign stack, and so on. LiteLLM simply gives you a cleaner gateway pattern when multiple models and providers are involved. For EU AI compliance, that can be valuable, but only when it reduces complexity rather than adding another moving part for no reason.
At this point, EU AI compliance should no longer feel like an abstract legal burden. We have the regulatory frame, the deployment postures, the data layer, the workflow layer, and the anonymization options. Now, we’d like to focus on what can you actually build with all of this.
In practice, most production AI apps in Europe fall into three repeatable patterns: document-heavy workflows, calculation-heavy workflows, and conversational workflows with grounded context. Each one can run on the architecture above, whether you choose a sovereign, pragmatic, or hybrid Posture. And each one is realistic enough to ship in a focused six-week cycle.
Document-heavy workflows are one of the most common places where AI creates immediate value. The shape is familiar: documents arrive, someone needs to read them, extract information, validate the result, route the case, and write the final data back into a system of record.
This pattern fits use cases like invoice intake, contract review, claims processing, KYC document review, supplier onboarding, and RFP response. The exact document type changes, but the workflow stays almost the same.
For EU AI compliance, the important point is that document automation cannot stop at extraction. The system also needs validation, audit logs, human review paths, and clear rules for when personal data can reach a model.
A document-heavy workflow usually follows this path:
| Step | What Happens | Why It Matters |
|---|---|---|
| Trigger | A document arrives through an email gateway, S3/MinIO upload event, API call, scan, or n8n watch on a shared inbox. | Gives the workflow a clear starting point and lets every document enter through a controlled channel. |
| Parse | Docling extracts structured content from PDF, Office files, or images. | Turns messy documents into usable text and structure before the model sees them. |
| Anonymize | In Posture C, Presidio middleware redacts or pseudonymizes PII before the model call. | Reduces exposure when the workflow may use a cross-border or non-sovereign model route. |
| Extract | FastAPI calls Mistral or Claude with a structured-output schema, usually enforced with Pydantic. | Keeps model output predictable instead of returning free-form text that downstream systems cannot trust. |
| Validate | A Postgres view checks the extracted data against business rules. | Prevents incorrect or incomplete extraction from moving forward automatically. |
| Route | n8n sends the item to a human review queue, auto-approval queue, or rejection path based on confidence and validation results. | Makes automation safe by separating clear cases from uncertain ones. |
| Writeback | Approved data lands in the customer’s system of record, such as CRM, ERP, or accounting software. | Turns extraction into a real business action, not just an AI-generated summary. |
| Audit | Every important step writes to the Postgres audit_log. | Creates the evidence trail needed for monitoring, review, and compliance. |
The key idea is that the LLM is only one part of the system. It extracts or classifies information rather than own the whole process, while Postgres validates, n8n routes, FastAPI controls the model call, humans review uncertain cases, and finally the audit log records what happened.
That separation makes the workflow easier to operate and easier to defend under the EU AI Act and GDPR together.
A document-heavy workflow should be judged by business outcomes associated with these core metrics:
These metrics prevent the usual AI trap: celebrating a good demo while ignoring whether the workflow actually saves time, reduces manual review, or lowers operational cost.
The most important metric is usually not extraction accuracy alone. A system can be 95% accurate and still be unusable if the remaining 5% creates expensive errors. That is why accuracy should be paired with confidence thresholds, review queues, and cost-per-document tracking.
A document AI workflow under EU AI compliance succeeds when extraction, validation, review, and audit work together. If you only build the extraction step, it’s just a demo. But when you have a fully-functional loop, it’s a production workflow. However, you should watch these potential pitfalls:
Calculation-heavy workflows look like AI projects from the outside, but they are usually decision systems at the core. Structured data flows in, rules are applied, scores are calculated, and a decision is written back into a system of record.
This pattern fits use cases like credit decisions, insurance pricing, loan eligibility, claims scoring, supplier risk scoring, and product classification. The business problem may sound complex, but the architecture should stay disciplined: use deterministic rules where rules are enough, and use the LLM only where judgment, explanation, or ambiguity handling is actually needed.
For EU AI compliance, this distinction matters. If the system affects access to finance, insurance, employment, education, housing, or other essential services, it may fall into a high-risk category. That means transparency, human oversight, auditability, and explainability cannot be added later. They need to shape the workflow from the very beginning.
A calculation-heavy workflow under EU AI compliance should incorporate this architecture:
| Step | What Happens | Why It Matters |
|---|---|---|
| Trigger | The workflow starts from an API call, n8n webhook, or scheduled batch job in Dagster. | Gives the system a controlled entry point for structured data. |
| Pre-Validate | A Postgres view checks whether all required input fields are present and usable. | Prevents incomplete or malformed data from entering the decision flow. |
| Calculate | Postgres views and generated columns produce derived values. Logic that does not fit SQL moves to FastAPI. | Keeps calculations close to the data and makes rules easier to audit. |
| Decide | Deterministic rules in Postgres handle the bulk of decisions. The LLM is used only for genuinely ambiguous cases. | Reduces cost, risk, and unpredictability. |
| Explain | If the decision is high-stakes or falls under Annex III high-risk areas, the LLM generates a human-readable explanation that cites the rule path. | Supports transparency and human review. |
| Writeback | The decision and explanation are written back into the system of record. | Turns the calculation into a controlled business outcome. |
| Audit | The full rule path and LLM-generated explanation are stored in the Postgres audit_log. | Creates evidence for review, dispute handling, and compliance. |
The most important design choice is where the actual decision logic lives. In this pattern, Postgres handles the core rules: eligibility, scoring, thresholds, validation, and calculations. FastAPI handles model calls and any logic that does not fit cleanly into SQL. n8n coordinates the workflow and moves the result to the right place.
This keeps the system predictable. It also makes the architecture easier to explain under the EU AI Act and GDPR together.
This pattern is most often misclassified as a pure AI workflow. In reality, most of it is not AI. Around 80% of the work is a rules engine in Postgres. The LLM enters at one specific point: generating a clear explanation, helping with a borderline case, or handling an ambiguous input that deterministic rules cannot resolve safely.
That framing changes everything. You rebuild the decisioning logic as Postgres views and use AI for explanation and ambiguity rather than the core decision. This produces a faster, cheaper, and more auditable system and makes EU AI Act obligations easier to satisfy. Since Article 13 focuses on transparency and Article 14 focuses on human oversight, both are easier to support when the rule path is explicit, inspectable, and stored in SQL — not hidden inside a vague model response.
A calculation-heavy workflow should be measured like a decision system using these metrics:
These metrics keep the project grounded. A good calculation-heavy workflow should not only use AI. What it really should do is to make decisions faster, reduce manual review, preserve control, and make explanations easier to produce.
And the most sensitive metric is often explanation quality. If the explanation does not match the actual rule path, it creates a compliance risk. That is why explanations should be generated from structured decision data rather than from an open-ended prompt that guesses why the decision happened.
Conversational workflows are what many teams imagine first when they think about AI apps: an employee or customer asks a question, the system retrieves relevant information, generates an answer, cites sources, and sometimes proposes an action.
This pattern fits HR self-service, internal IT support, customer-facing knowledge assistants, research tools, policy assistants, and internal Q&A. It looks simple on the surface, but production quality depends on one thing: the assistant must answer from approved context, not from memory or guesswork.
For EU AI compliance, that makes grounded retrieval, permissions, audit logs, and retention rules essential. A chatbot that can answer anything is not the goal. A chatbot that can answer the right questions, using the right sources, for the right user — and decline when it lacks evidence — is the goal.
An AI conversational workflow architecture follows this path:
| Step | What Happens | Why It Matters |
|---|---|---|
| Frontend | A Next, Nuxt, or Astro chat interface streams the response to the user. | Gives users a familiar interaction layer without changing the backend compliance model. |
| Auth | Keycloak issues a JWT with roles, departments, and permissions. | Carries user identity and access rights into the workflow. |
| Retrieve | Qdrant or pgvector is queried with a permission-aware filter from the JWT. | Ensures the system retrieves only documents the user is allowed to see. |
| Construct Prompt | FastAPI builds the prompt using retrieved chunks, system instructions, and the user query. | Keeps prompt construction controlled and consistent. |
| Generate | Mistral handles routine questions; Claude on Bedrock handles harder reasoning when allowed. | Routes the workload based on task complexity and data tier. |
| Cite | The structured response includes source IDs, and the UI links back to the original documents. | Lets users verify the answer instead of trusting unsupported text. |
| Action | If the assistant proposes an action — file a ticket, schedule a meeting, write to a system — a human approval gate comes before execution. | Prevents the assistant from taking sensitive actions without oversight. |
| Audit | The query, retrieved sources, response, citations, and action are written to the Postgres audit_log. | Creates a traceable record for monitoring, review, and compliance. |
This architecture is deliberately strict, because neither the frontend nor the model decides what the user can see. Access control happens long before context reaches the model.
Permission-aware retrieval is the core of this pattern. In a demo, all documents often sit in one index, and the assistant retrieves whatever looks semantically relevant. That is dangerous in a real company. It means an HR question might surface finance documents, an employee might see executive files, or a customer-facing assistant might retrieve internal notes.
In production, every document in Qdrant should carry metadata: department, role visibility, tenant, source system, security classification, and any other access rule that matters. When a user asks a question, the JWT from Keycloak travels with the request. Qdrant then filters retrieval based on that user context.
So the assistant does not retrieve “the best matching document” in general. It retrieves the best matching document the user is actually allowed to access.
Without this layer, the assistant can leak confidential information and break the EU AI compliance. However, using it helps keep access boundaries intact. So, consider these roles:
The only way to measure the efficiency of a conversational workflow is associated with two things: trust and usefulness. Therefore, consider these metrics:
These metrics keep the assistant honest. With a high citation rate, you workflow indicates that answers are grounded. A healthy escalation rate illustrates that the system knows when not to answer. Time saved shows whether users actually benefit from using the AI workflow. And low hallucination rate proves that the assistant is safe enough to keep expanding.
Just as in case of other workflows, conversational AI becomes production-ready only when retrieval, permissions, citations, action approvals, and audit logs work together. Other aspects that can help you keep your system usable, useful, and compliant in the EU include:
By this point, the architecture may look large. It includes workload classification, deployment postures, Postgres guardrails, n8n workflows, FastAPI as the LLM gateway, audit logs, anonymization, and three production patterns. But you do not need to build everything at once.
The right first step is not a six-month strategy project. It is one focused week that turns EU AI compliance from an abstract concern into a concrete implementation plan. The goal of week one is simple: classify the workload, choose the posture, define success, and stand up the foundation for one production AI workflow.
Start with the data, not the model. List the AI workflows you want to build and classify each one using the tier model from earlier:
| Tier | Typical Data | Default Direction |
|---|---|---|
| T1 Strict | Health data, defence, public-sector citizen data, high-risk AI with EU citizens | Sovereign only |
| T2 Sensitive | HR data, customer records, finance, contracts, personal data at scale | Sovereign or explicitly accepted EU-bound provider |
| T3 Standard | Internal documents, operational data, non-sensitive business records | Pragmatic or hybrid |
| T4 Public | Public data, marketing content, anonymized analytics | Any posture |
This is the conversation that drives every architectural decision. If you skip it, you will end up debating tools before you understand the risk.
Once the workload is classified, choose the right deployment posture. Most projects will land in one of three options:
Document the choice. Do not leave it as an informal technical preference. The posture should be tied to the data tier, customer requirements, and risk acceptance.
Do not start with five KPIs. Start with one. Each workflow needs a single success metric that proves whether the project was worth building. For example:
This metric becomes the anchor. It keeps the project from turning into an AI experiment with no measurable outcome.
By day four, you should move from planning to infrastructure. For a practical starting setup, two Hetzner CCX boxes are enough:
You do not need a perfect enterprise platform on day one. You need a controlled EU environment where the first workflow can run, log actions, and connect to the rest of the stack.
By the end of day five, the foundation should be running. The first version of the stack should include:
At this point, you are not finished. But you have the foundation: a system that can accept requests, route work, call models through a controlled layer, and preserve evidence without breaking EU AI compliance.
In week two, choose one of the three patterns from this guide:
Then build it from trigger to writeback. The goal is an end-to-end workflow in staging that proves the architecture works with real inputs. Don’t think about a polished interface yet.
Once the workflow works in isolation, connect it to the customer’s actual systems:
This is where many AI projects get harder, because integration is usually the bottleneck.
By week five, the workflow should be ready for controlled production use. This means you have to deal with real users and traffic, enabled audit logs, active error workflows, monitored dead-letter queues, defined human review paths, and completed basic training.
There is no need to wait for the entire AI roadmap to be complete. You can ship one useful workflow and learn from production.
In week six, compare the workflow against the success metric from day three. At this point, you only have to ask whether your workflow moves the metric enough to justify expansion.
If yes, extend it or build the next workflow.
If no, diagnose the bottleneck before adding more AI.
This is the Genixly Cycle: six weeks, one shipped app, and one measurable business outcome. That is how EU AI compliance becomes part of delivery instead of a blocker at the end.
After reading countless AI agency blog posts and seeing enough failed proof-of-concepts, one pattern becomes hard to ignore: most AI projects fail before the model even matters.
The problem is rarely that the model is not “smart enough.” The problem is that the project starts in the wrong place. Many teams begin with a tool, a model, or a demo. Then they try to add EU AI compliance, GDPR controls, audit logs, and human oversight afterward. That order creates fragile systems.
We would build it differently.
Most agencies build AI strategy decks. We ship software. A roadmap has value only if it leads to a working system: one production workflow, connected to real tools, monitored properly, and measured against one business outcome.
Most agencies pick the model first. We classify the workload first. The serious questions are not “Claude or Mistral?” The serious questions are ones that help you understand what data flows through your AI system, which regulatory tier it belongs to, where inference can potentially occur, and what evidence you will need if a customer or auditor asks.
Most agencies hide business logic in application code. We put the rules where they are easier to enforce and audit: Postgres. Eligibility, scoring, validation, calculations, access boundaries, and audit trails should not be scattered across frontend components, n8n workflows, and Python services. When the rules live close to the data, the system becomes clearer from the perspective of the AI regulation in Europe.
Most agencies treat compliance as a final wrapper. We treat it as the architecture itself, where append-only audit logs are used from day one, permission-aware retrieval takes place from the very beginning, FastAPI acts as the controlled LLM gateway, workload classification takes place before infrastructure, and human review paths are where the risk requires them.
That is the real shift behind this guide and the Genixly Cycle. EU AI compliance is not a brake on AI implementation. It is a design discipline that forces teams to build systems that can explain themselves, protect data, survive audits, and keep working after the demo is over.
None of this requires exotic technology. As shown above, the components are available and the patterns are repeatable when you create compliant AI apps in Europe. The hard part, however, is sequencing, knowing what to build first, what to keep simple, what to document, and where not to improvise.
If you don’t want to build this architecture yourself, ask us to do it for you. We’ll use our proven workflow to design, ship, and document AI apps that meet EU AI compliance requirements from day one.
EU AI compliance means building, deploying, and operating AI systems in a way that satisfies the main European legal requirements — especially the EU AI Act and GDPR. In practice, it covers more than legal documents. It affects architecture, data flows, model hosting, audit logs, human oversight, risk management, and whether personal data can leave the EU.
GDPR focuses on personal data: how it is collected, processed, stored, transferred, protected, and deleted. The EU AI Act focuses on AI systems themselves: what use cases are banned, which systems are high-risk, and what obligations apply to those systems. A compliant AI app in Europe usually needs to satisfy both frameworks at the same time.
Not always. Public, anonymized, or low-risk data may allow more flexible deployment options. However, personal data, sensitive data, and high-risk AI workloads often require stricter controls. In many cases, EU hosting or EU-bounded inference becomes the safer default, especially when GDPR transfer rules, customer requirements, or sector-specific regulations apply.
Sometimes, but not by default. You need to classify the workload first. If the system processes sensitive personal data, health data, public-sector data, or high-risk decisioning data, a US-hosted API may create legal and procurement problems. EU-bounded options like Claude on Bedrock Frankfurt can be acceptable for some workloads, while strict cases may require fully sovereign infrastructure.
The safest architecture is usually a sovereign-first setup: EU-hosted infrastructure, EU-hosted inference, local embeddings, local vector search, self-hosted workflow automation, append-only audit logs, and permission-aware retrieval. This is the strongest option when CLOUD Act exposure is unacceptable.
Because not all AI workloads carry the same risk. A public marketing-content assistant does not need the same architecture as a medical triage tool or an HR decisioning system. Workload classification helps you decide whether you need a sovereign setup, a pragmatic EU-bounded frontier model, or a hybrid architecture. Without classification, teams often over-engineer simple workflows or under-protect sensitive ones.
High-risk AI systems are applications that can significantly affect people’s rights, access to services, or life opportunities. Common examples include hiring, credit scoring, insurance underwriting, education assessment, access to essential services, healthcare-related use cases, law enforcement, migration, and justice. These systems require stronger controls, including risk management, technical documentation, logging, human oversight, and post-market monitoring.
No. Pseudonymization reduces risk, but it does not remove GDPR obligations. If the original identity can be restored through a mapping table, Redis key, or another additional source, the data is still personal data. That means cross-border transfer rules, legal basis, DPIA documentation, and GDPR safeguards still apply.
A compliant AI app should log the key events needed to reconstruct what happened: who triggered the action, what workflow ran, what data was used, which model handled the request, what output was produced, whether human approval was required, and what happened after the decision. For high-risk systems, append-only audit logs in Postgres are a much stronger foundation than scattered workflow or application logs.
Start with one workflow, not a full AI transformation program. Classify the workload, choose the correct deployment posture, define one success metric, deploy the core stack, and build one end-to-end workflow with audit logs, error handling, and human review where needed. This turns EU AI compliance into an implementation discipline instead of a last-minute legal blocker.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.
Unlock all features and see how our tools can transform your financial reporting and analytics.

