Genixly team
-
March 12, 2026
What Are the Best GEO-Tracking Tools? 26 Solutions for 2026 (Pros, Cons, & The Only Replacement You Need)
Lear more
Explore cloud data warehouse architecture. Discover its core principles and components, such as scaling, automation, and integrations across top vendors.

In this article, we are going to break down the core principles of the cloud data warehouse architecture, such as the storage format, processing model, resource management, etc.
Since every modern cloud data warehouse is built upon a shared architectural foundation, they emphasize scalability, automation, and data interoperability. Yet, beneath this common framework, each platform introduces its own unique design choices and optimizations. Understanding these distinctions is critical for enterprises selecting the right system for their analytical needs, especially those balancing performance, governance, and multi-cloud flexibility.
Below are the core architectural principles of cloud data warehousing that define leading solutions, along with the key variations seen among vendors such as Snowflake, Databricks, Amazon Redshift, Google BigQuery, Azure Synapse Analytics, Qlik, Informatica, and ScienceSoft.
At the foundation of every cloud data warehouse is its storage layer, designed to hold vast volumes of data efficiently while enabling rapid analytical access. Most platforms use columnar storage formats, which organize data by column rather than by row. This approach dramatically improves query performance for analytical workloads because only the necessary columns are scanned, compressed, and retrieved. It also enhances data compression, reducing storage costs without sacrificing speed.
The difference between columnar and row-based (or linear) data storage formats is about how data is physically organized and accessed inside a database or data warehouse. Let’s break it down clearly:
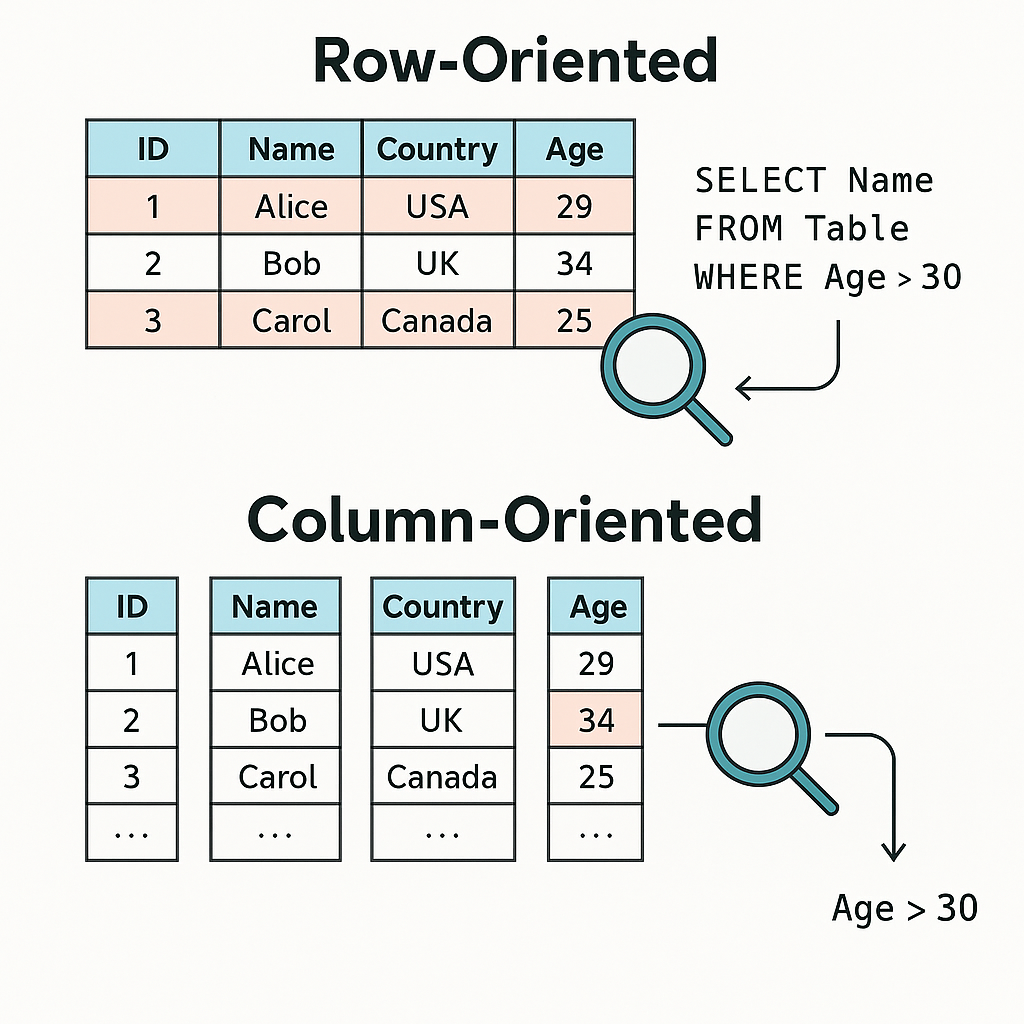
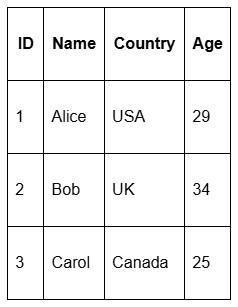
In a row-based system, the storage would look like this:
[1, Alice, USA, 29], [2, Bob, UK, 34], [3, Carol, Canada, 25]
ID: [1, 2, 3]
Name: [Alice, Bob, Carol]
Country: [USA, UK, Canada]
Age: [29, 34, 25]While columnar compression is standard across vendors, variations in supported formats and flexibility distinguish each platform.
The result is a storage architecture that is not only efficient but also adaptive — capable of handling billions of records across multiple data types and formats in near real time.
The heart of a cloud data warehouse lies in its processing model, which determines how queries are executed and scaled. Most leading platforms rely on Massively Parallel Processing (MPP) — an architecture where workloads are distributed across multiple compute nodes that work simultaneously on different parts of the query.
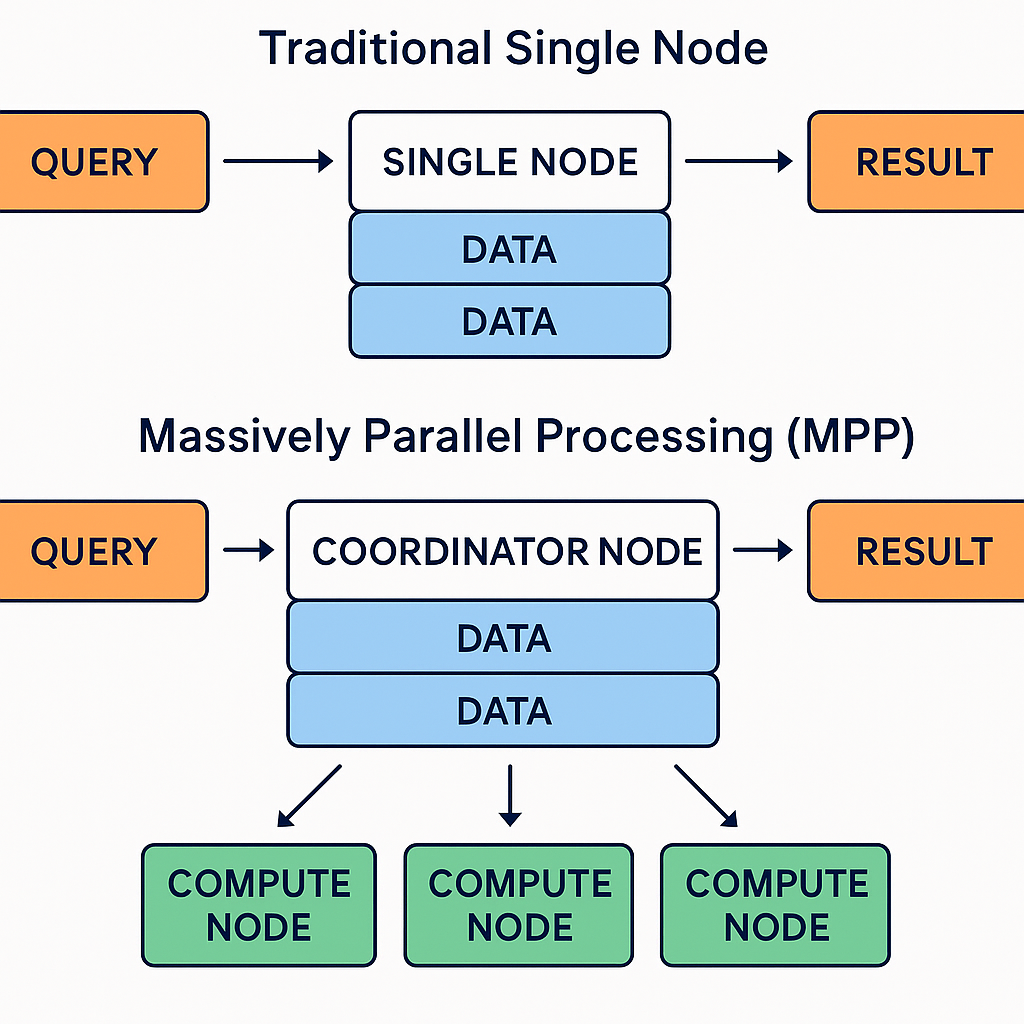
Massively Parallel Processing (MPP) is a way of dividing big computing tasks — like analyzing a huge dataset — into smaller pieces and working on them at the same time, rather than one after another.
Think of it like this:
Imagine you have to count all the red marbles in a million boxes.
That’s what MPP does, except instead of people, you have compute nodes — powerful servers or virtual machines — each responsible for a portion of the data.
Because all nodes are working in parallel, not sequentially, a query that would normally take minutes or hours on a single server can complete in seconds on an MPP system. This makes MPP the backbone of modern cloud data warehouses like:
The MPP architecture is what makes cloud data warehousing truly enterprise-ready: it scales linearly, ensuring consistent performance whether the workload involves 10 million or 10 billion rows.
One of the defining advantages of a data warehouse in the cloud is independent scaling of compute and storage. This separation allows organizations to manage resources based on need: scaling compute up during intensive operations and scaling down when workloads are light, all without affecting stored data.
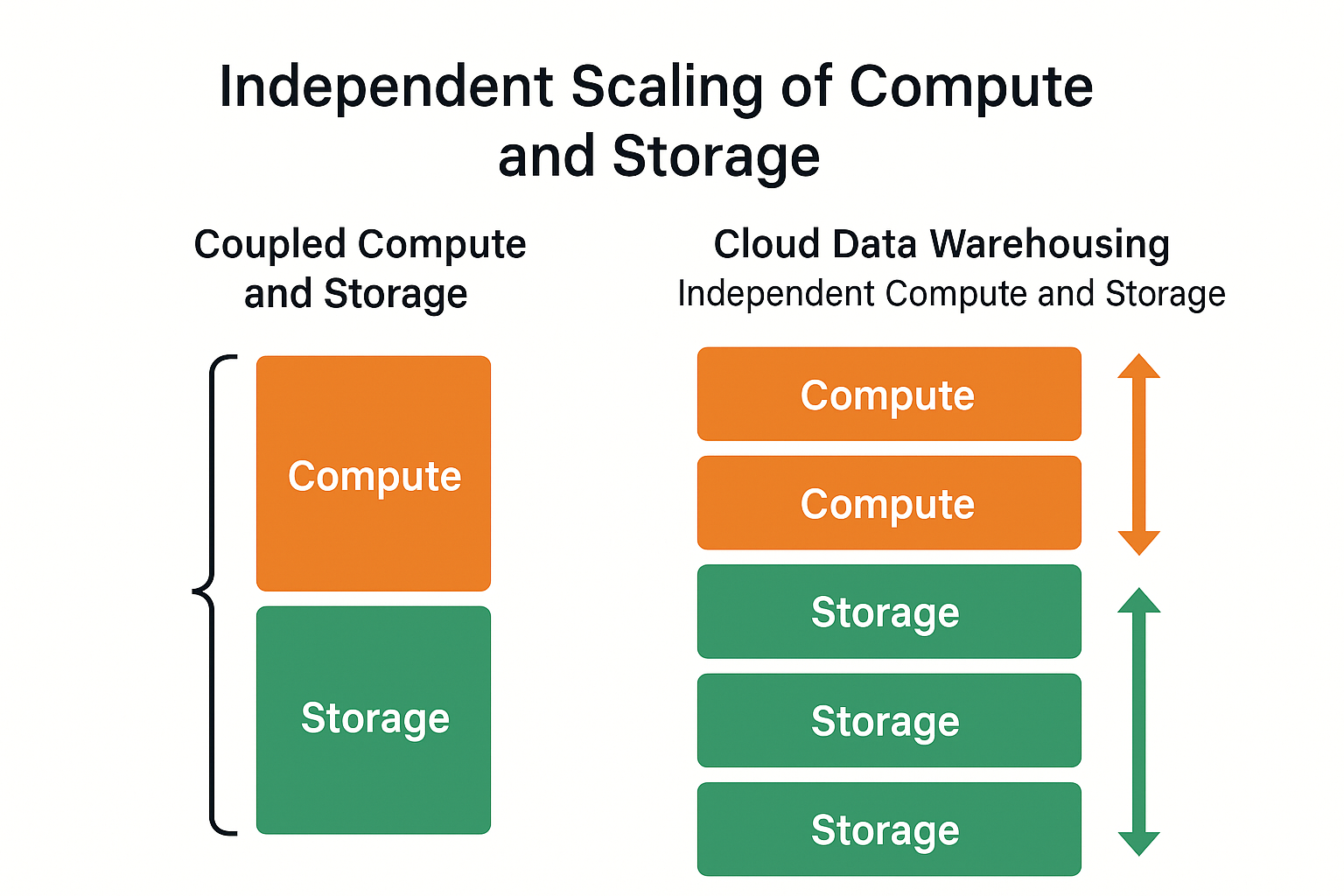
In most traditional systems, compute (processing power) and storage (where your data lives) are tightly linked — like a single machine with a fixed hard drive and CPU. If you want faster performance, you need to upgrade the whole system — even if you don’t need extra storage space.
A cloud data warehouse works differently. It separates compute from storage, meaning these two components can grow or shrink independently.
Here’s how that helps:
If you suddenly have a big job, for example, a huge monthly sales report, you can scale up compute power (add more virtual workers) to finish the task quickly. Once the workload is done, you can scale down to save money.
Meanwhile, your data remains safely stored the entire time — unaffected by these changes.
This aspect of the cloud data warehouse architecture empowers businesses with the ability to handle busy periods efficiently (using more power when needed) and stay cost-effective during quiet times. Here is how core vendors deliver speed when you need it and savings when you don’t:
This elasticity makes the cloud vs. on-premise data warehouse comparison particularly striking: where on-prem systems are limited by physical hardware, cloud solutions deliver near-infinite flexibility. For global enterprises, it means being able to handle regional surges in data processing, such as Black Friday traffic or quarterly financial closes, without overprovisioning or downtime.
Automation is what makes a modern cloud data warehouse so powerful. Instead of people manually moving, cleaning, and optimizing data, the system handles much of it automatically — 24/7. Let’s break down how this works in practice and what the key automated processes actually do.

Every organization gathers data from many different places — CRMs, ERPs, eCommerce platforms, IoT sensors, and APIs. In the past, someone had to manually export and upload these files. Now, automation handles this entire process.
Modern cloud data warehouse services continuously pull data from multiple sources in real time. When new records appear — like a new sale, transaction, or sensor update — they’re automatically captured and stored in the warehouse. This ensures that reports and dashboards always reflect the latest information without human intervention.
Once data is collected, it’s rarely ready for analysis. It may have duplicates, missing fields, or inconsistent formats. Automated transformation pipelines fix this by applying predefined rules and machine learning logic that clean, format, and organize the data.
For example, if one source lists “U.S.” and another says “United States,” automation standardizes both. It might also convert currencies, merge duplicates, and check for errors. These transformations happen continuously as data flows in, so analytics teams always work with clean, reliable datasets.
In traditional systems, database administrators had to manually optimize queries and balance workloads to keep performance high. In a cloud data warehouse, this process is automated.
The system monitors query patterns, identifies bottlenecks, and auto-adjusts computing resources based on demand. If many users run reports at the same time, the system scales up compute power automatically — and scales back down when the load decreases. This ensures fast results without wasted resources or downtime.
Governance is all about knowing where your data comes from, who uses it, and how it changes. Metadata-driven orchestration automates this tracking. Metadata is simply “data about your data” — like the source, owner, or timestamp of a dataset.
In a modern warehouse, every dataset, table, and query is automatically cataloged. This makes it easy to trace data lineage (its full journey from source to report), maintain security rules, and prove compliance during audits. Automated governance not only saves time but also ensures transparency and accountability across teams.
When all these automated parts — ingestion, transformation, performance tuning, and governance — work together, you get end-to-end orchestration. This means data moves smoothly from its source to dashboards without manual intervention.
Solutions with modern cloud data warehouse architecture manage this entire flow intelligently.
Automation in data warehousing is not just operational — it’s strategic. By minimizing manual processes, enterprises can reduce human error, enhance data quality, and shorten time-to-insight. The result is a system that doesn’t just store data — it actively manages, cleans, optimizes, and secures it, allowing teams to focus on insights rather than maintenance.
Modern businesses no longer deal with just clean, table-like data — they generate information from emails, social media, sensors, web apps, and countless other sources. To stay relevant, cloud data warehouse architecture has evolved to handle not just structured data, but also semi-structured and unstructured data. Each type serves a different purpose and requires a unique approach to storage and analysis. Let’s break them down in plain language.
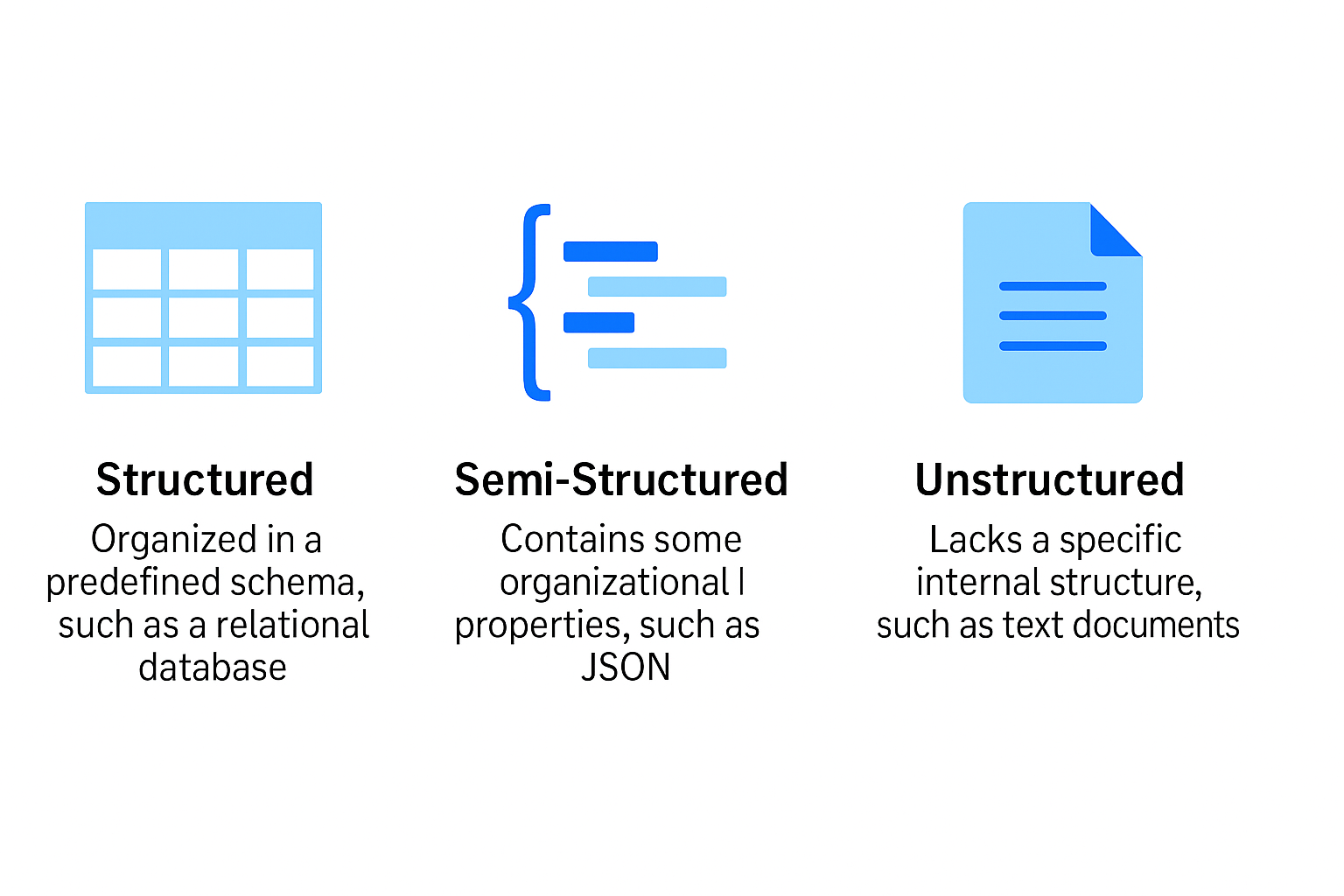
Structured data is the most organized and easiest type of data to manage. It fits neatly into rows and columns — like a spreadsheet or database table.
Examples:
Each record follows a fixed schema, meaning every column (like “Name,” “Price,” or “Date”) always contains the same type of information. Traditional data warehouses — such as older SQL-based systems — were built specifically for this kind of data.
Why it matters: Structured data is simple to search, sort, and aggregate using standard SQL queries. It’s perfect for generating reports, dashboards, and KPIs.
Semi-structured data doesn’t fit perfectly into tables, but it still has some internal organization — often using tags, keys, or nested structures.
Examples:
Unlike structured data, the schema here is flexible — fields can vary between records. For instance, one customer record might have a “phone” field, while another has “email only.”
Why it matters: Semi-structured data reflects the real world — dynamic, irregular, and diverse. Being able to process it efficiently gives organizations a fuller, more realistic picture of their operations and customer behavior.
Unstructured data is the most complex form. It doesn’t follow any consistent format or schema, making it harder to store and analyze.
Examples:
In traditional systems, this kind of data had to be stored separately — usually in data lakes or file repositories. But modern cloud data warehouses increasingly integrate with data lakehouse architectures, allowing them to manage and analyze unstructured content alongside structured data.
For example, AI and machine learning models can now extract meaning from images (like recognizing product defects) or from text (like analyzing customer sentiment), feeding those insights back into the warehouse for unified reporting.
Why it matters: Unstructured data holds a vast amount of untapped value. Being able to store, search, and analyze it — alongside structured and semi-structured data — helps businesses make smarter, more comprehensive decisions.
Traditional warehouses could handle only the simplest, most predictable data. Modern cloud data warehouse platforms break that limitation. They bring together structured, semi-structured, and unstructured data into one environment — allowing enterprises to analyze transactions, logs, and even social media content within a single system.
This data diversity enables enterprises to merge traditional BI with machine learning and real-time analytics, unifying operational, customer, and market data under one analytical framework. For global businesses, it translates into smarter personalization, faster forecasting, and deeper visibility into complex ecosystems.
Integration is one of the biggest advantages of a cloud data warehouse — and one of the main reasons businesses choose it over traditional on-premise systems. In simple terms, integration means that your data warehouse doesn’t live in isolation. It connects effortlessly to the tools and platforms your organization already uses — analytics dashboards, machine learning models, APIs, and automation systems — forming a unified data ecosystem.
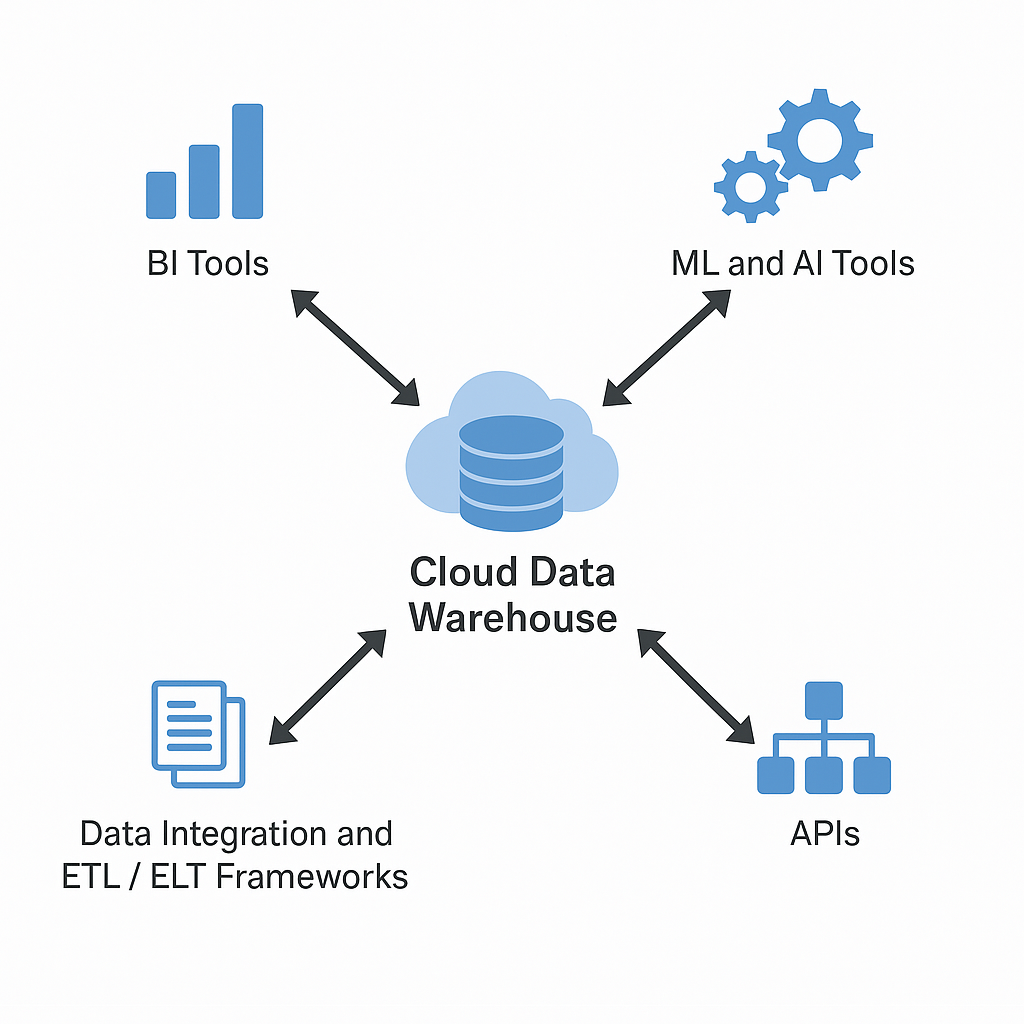
Here’s how integration works and why it’s so valuable:
A cloud data warehouse acts as the central hub for storing and organizing data, but BI tools like Power BI, Tableau, Looker, or Qlik are what turn that data into visual reports and dashboards.
Modern warehouses offer native connectors and APIs that allow these BI tools to plug in instantly — no complex setup or manual data export needed. As soon as data updates in the warehouse, the dashboards reflect those changes in real time.
This integration ensures that everyone — from marketing and sales to finance and operations — works from the same, accurate, and up-to-date information. It transforms the warehouse into a live analytical engine rather than a static storage system.
Today’s cloud data warehouse solutions go beyond analytics; they power machine learning and AI workflows. Modern platforms like Google BigQuery, Snowflake, and Databricks can connect directly to AI tools such as TensorFlow, PyTorch, or Vertex AI.
This integration allows data scientists to train models directly on warehouse data, without needing to move large datasets elsewhere. For example, a retailer could use warehouse data to train a model predicting customer churn or optimizing inventory levels. Once trained, those models can send predictions back into the warehouse — closing the feedback loop.
By blending data warehousing and AI, organizations move from simply understanding what happened to predicting what will happen next.
APIs (Application Programming Interfaces) are what allow systems to talk to each other. A cloud data warehouse equipped with strong API support can integrate with CRMs, ERPs, marketing tools, eCommerce platforms, and external databases.
This means a new customer purchase, shipment update, or campaign result can flow automatically into the warehouse the moment it happens. Similarly, insights generated inside the warehouse can be pushed back out to other systems — for example, sending personalized product recommendations to a marketing app or alerting sales teams about high-value leads.
This real-time data exchange makes cloud warehouses an active part of daily operations, not just a background reporting tool.
Before data can be analyzed, it must be collected, cleaned, and prepared — a process handled by data integration tools or ETL/ELT frameworks (Extract, Transform, Load / Extract, Load, Transform).
Cloud platforms integrate seamlessly with solutions like Informatica, Talend, Fivetran, and Qlik Data Integration, which automate the movement of data from dozens of sources into the warehouse. These tools can process both real-time streams and scheduled batch loads, ensuring that data across systems remains synchronized and analysis-ready.
By automating integration, cloud warehouses eliminate silos — creating a single source of truth where all data converges, structured and ready for analytics or machine learning.
Integration is what turns a cloud data warehouse from a storage system into the beating heart of an organization’s data strategy. Through deep connections with BI platforms, AI frameworks, APIs, and ETL tools, it enables a seamless flow of information across the entire business ecosystem.
The result? Faster insights, smarter automation, and a fully connected data infrastructure where analytics, prediction, and action happen continuously — all powered by the cloud:
This interconnectivity ensures that the data warehouse serves as the central nervous system of the enterprise.
Despite the differences, every major vendor converges around the same approach to the cloud data warehouse architecture, creating a scalable, secure, and intelligent data foundation that supports analytics and AI at a global scale. Each innovation — from Databricks’ open lakehouse format to Snowflake’s multi-cluster concurrency or Qlik’s automation orchestration — contributes to a shared vision: transforming data warehouses into self-optimizing ecosystems.
For large enterprises, this architectural maturity means that a cloud data warehouse is no longer just a database — it’s a living, adaptive layer that connects every function of the business, turning raw data into actionable intelligence, faster than ever before. For deeper context on related concepts, explore our Glossary of Ecommerce Terms.
Our blog offers valuable information on financial management, industry trends, and how to make the most of our platform.

